
Chain of Thought prompting is by far one of the most well-known, and effective prompt engineering methods. I’ve been a bit intimidated to write about it, partly because of its importance, and partly because Chain of Thought prompting can be a little complex. Unlike other prompt engineering methods, there isn’t a single Chain of Thought prompt template.
Rather, there are various ways to implement Chain of Thought prompting. From adding a simple line of text like “think this through step-by-step” to setting up more elaborate prompts using Chain of Thought prompting combined with Self-Consistency prompting.
In this guide, we’re going to dive deep into what Chain of Thought prompting is all about. We’ll look at the original paper that introduced the concept and explore different ways to implement it, including newer methods like Auto Chain of Thought (Auto-CoT). We’ll include a ton of examples and templates that you can plug and play to get a better understanding of what Chain of Thought prompting actually is, and how you can use it to get better outputs from LLMs.
What is Chain of Thought prompting
Chain of Thought prompting is a prompt engineering method that enhances the reasoning capabilities of large language models (LLMs) by encouraging them to break down their reasoning into a series of intermediate steps. In addition to providing an answer, Chain of Thought prompting requires the model to explain how it arrived at that final answer, offering more transparency and potentially improving accuracy.
At its core, Chain of Thought prompting encourages the model to think through the problem in a step-by-step manner, which is supposed to mimic how humans break down complex problems.
The example below demonstrates a simple Chain of Thought prompting example. Both prompts use few-shot prompting, but the difference is on the left side, the answer is just given, without any reasoning steps ("The answer is 11."). On the right side, the answer is given along with the reasoning steps (highlighted in blue).

Before diving into examples, we should probably directly answer the question of why you should care about Chain of Thought prompting and how it can help you.
Why Chain of Thought prompting is helpful
Chain of Thought prompting provides four major benefits:
- Breaks down complex problems: Chain of Thought prompting enables LLMs to decompose complex problems into a series of intermediate steps. This step-by-step approach, in theory, allows the model to allocate more attention to each part of the problem, leading to more accurate reasoning.
- A glimpse into the model’s thought process: By seeing the reasoning steps that the model undertakes, users can better understand the model and debug if/when the reasoning paths go wrong.
- Widely applicable: Chain of Thought prompting has been successfully tested across a large and diverse set of tasks. It’s versatile enough to be applied to a variety of tasks that require any sort of reasoning.
- Easy implementation: While there is a wide range of ways to implement Chain of Thought prompting, there are a lot of very simple ways to do so.
Chain of Thought prompting examples
As mentioned before, Chain of Thought prompting is an extremely versatile prompt engineering method. It can be adapted in various ways, and several variants of this concept have been developed.
We’ll start with some of the more basic examples.
Zero-shot Chain of Thought example
The simplest way to implement Chain of Thought prompting is to include language that instructs the model to reason. The most popular version of this is adding the phrase "Let’s think step-by-step."
Other suggested and thoroughly tested thought-generating phrases include:
- "Let’s work this out in a step-by-step way to be sure we have the right answer."
- "First, let’s think about this logically."
Below is an example of zero-shot Chain of Thought prompting. No examples are used to demonstrate reasoning steps; only the reasoning phrase is added.

Below is a template in PromptHub you can use as well

Few-Shot Chain of Thought Example
Few-shot Chain of Thought prompting is when you provide the model with a few examples of reasoning steps in the prompt. The example reasoning steps included should be related to the problem you are having the model solve.
Few-shot Chain of Thought generally outperforms zero-shot Chain of Thought (see table below). Adding demonstrations can increase accuracy by up to 28.2% in some tasks.

Want nine examples? See below.
The highlighted text shows the few-shot reasoning examples.

Here’s another example for math word problems:
Plus a template in PromptHub:

DeepSeek-R1's training template to generate chain of thought steps
When the DeepSeek team was training their first reasoning model, DeepSeek-R1 they used the following template to generate chain of thought sequences. Access the template here.

Chain of Thought with Self-Consistency
If you’re not familiar with Self-Consistency prompting, you can check out our guide: Self-Consistency and Universal Self-Consistency Prompting.
Chain of Thought with Self-Consistency prompting takes a Chain of Thought prompt (could be zero-shot or few-shot) and runs it multiple times to generate various outputs. A Self-Consistency prompt is then used to select the most consistent answer.
This helps mitigate one-off reasoning errors and increases the reliability of the output.

Step-Back prompting
Step-Back prompting follows a similar pattern to Chain of Thought in that it prompts the model to generate high-level information about relevant concepts and facts before diving into the task.

Analogical prompting
Analogical prompting is one of my personal favorite prompt engineering methods. It is very similar to Auto-Chain of Thought prompting but doesn’t require a dataset of examples with various clusters to choose from (more on this later). Instead, it relies on the model to generate relevant and distinct examples and explanations before solving the problem at hand.

Thread of Thought
Thread of Thought (ThoT) builds on Chain of Thought prompting with an improved thought inducer that encourages the model to maintain a coherent line of thought across multiple turns.
This method is particularly helpful in longer question-and-answer settings and when using retrieval-augmented generation with large contexts. Other exampl use cases might involve dialogues or storytelling.
Rather than "let’s think step-by-step," the typical phrasing for Thread of Thought is "Walk me through this context in manageable parts, step by step, summarizing and analyzing as we go."

Contrastive Chain of Thought prompting
Contrastive Chain of Thought prompting is very interesting as it builds on the key principle of few-shot prompting: examples should be diverse. Contrastive Chain of Thought prompting adds both correct and incorrect examples to the Chain of Thought prompt to teach (show) the model how not to reason by demonstrating faulty logic next to correct reasoning.

Faithful Chain of Thought prompting
Faithful Chain of Thought prompting was designed to ensure that the reasoning chains generated accurately reflect the model’s actual process of arriving at an answer. The idea is that the generated reasoning in Chain of Thought prompts doesn’t always align with how the model actually computes the answer, leading to issues with faithfulness. For more info about when and why models aren't faithful to their reasoning chains—and why it matters—read our full article on Faithful Chain of Thought prompting.

Faithful Chain of Thought addresses this by using both natural language and symbolic reasoning (e.g., Python code) to arrive at a final answer. It’s a two-step process:
- Translate the natural language query into a symbolic reasoning chain.
- Use a deterministic solver to derive the final answer.


Tabular Chain of Thought (Tabular CoT)
Tabular Chain of Thought prompting is similar to Thread-of-Thought prompting in that it uses a different format for the reasoning step. Specifically, it employs a zero-shot Chain of Thought prompt that instructs the model to provide its reasoning in a structured format, typically using markdown tables.
This structured approach helps to improve the clarity and organization of the model's output, making the reasoning process easier to follow.

Chain of Thought prompting with reasoning models
Newer models like o1-preview and o1-mini from OpenAI have incorporated chain of thought prompting automatically via inference-time reasoning tokens. The way you prompt these models to reason is very different from non-reasoning models like gpt-4o.
Here are the most important things to know about chain of thought prompting with reasoning models. For more info, check out our full guide: Prompt Engineering with Reasoning Models.
Effectiveness of CoT Prompting:
Adding CoT prompts ("think step-by-step") for simple tasks can sometimes reduce performance by overcomplicating the reasoning process.
Below are the results from a code summarization task from the paper, Do Advanced Language Models Eliminate the Need for Prompt Engineering in Software Engineering?
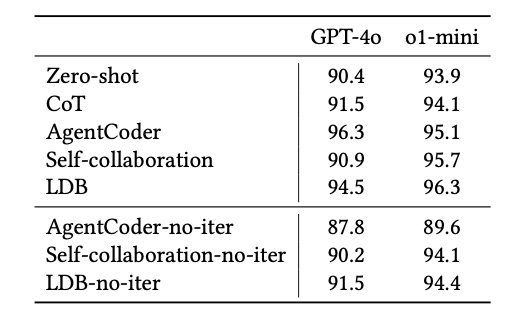
As you can see, the addition of CoT for o1-mini didn't change much.
Correlation between reasoning steps and performance:
Research has shown that increasing the number of reasoning steps for challenging tasks can improve performance in reasoning models. Explicitly instructing the model to "spend more time reasoning" correlates with higher accuracy and better outputs. This aligns with OpenAI’s guidance that more reasoning tokens often lead to better results.
“We have found that the performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute”
For example, in a recent paper, From Medprompt to o1: Exploration of Run-Time Strategies for Medical Challenge Problems and Beyond the researchers tested two prompts templates:
- A prompt that instructs the model to respond with less reasoning tokens.
- A prompt that instructs the model to respond with more reasoning tokens.
They found that as the number of reasoning steps increased, so did the accuracy.

Here are the two templates they tested:
The DeepSeek researchers came to a similar conclusion in the release paper for DeepSeek R-1.

Task complexity matters:
Also from Do Advanced Language Models Eliminate the Need for Prompt Engineering in Software Engineering? the researchers found that for tasks requiring five or more reasoning steps, reasoning models like o1-preview greatly outperform their non-reasoning counterparts.
On the other side, for simpler tasks with fewer reasoning steps, non-reasoning models like GPT-4o, which can deliver concise and accurate results without unnecessary reasoning, performed better.
Here are the numbers, in relation to code generation tasks:
Output consistency challenges:
Reasoning models can sometimes include reasoning "leakage" in their outputs, where the reasoning tokens appears in the response. This is something to keep an eye out for when testing.
For tasks requiring concise and structured outputs, such as code generation, this can require the need for post-processing, which can be annoying. Non-reasoning models, by contrast, are less prone to this issue.
Automatic Chain of Thought prompting
This method variant is important enough to require its own section!
A key component of few-shot Chain of Thought prompting are the reasoning demonstrations sent along with the prompt.
Automatic Chain-Thought (Auto-CoT) was designed to overcome the limitation of manually creating demonstrations for the Chain of Thought prompt. It generates the reasoning demonstrations automatically, eliminating the work needed to manually write them.
The key idea behind Auto-Chain of Thought prompting is that diversity in the questions and reasoning demonstrations used is critical. Using diverse examples is a general best practice in few-shot prompting, as it ensures the model is prepared for a variety of new problems.
Auto-Chain of Thought prompting first selects diverse examples from a dataset and then generates reasoning chains for the demonstrations.
How Auto-Chain of Thought prompting Works
Auto-CoT has 2 main steps:
- Question clustering: Questions from a given dataset of potential options are divided into clusters. Clustering the examples helps mitigate the risk of providing examples that are too similar, which could lead the model to overfit its output.
- Demonstration Sampling: A question from each cluster is chosen and a reasoning chain is generated using a zero-shot-Chain of Thought prompt.
Here’s what the 2-step flow looks like:

Auto-Chain of Thought prompting performance
Let’s see how a few of these Chain of Thought prompting methods stack up across 10 public benchmarks! For some context Manual-CoT = Few-Shot Chain of Thought where the examples are manually written.
Automated Chain of Thought Generation with AutoReason
AutoReason builds on the strengths of Chain of Thought (CoT) prompting by dynamically generating reasoning traces tailored to any query or task.
I personally like it much better than the Auto-CoT framework.
The key idea behind AutoReason is to dynamically create reasoning steps for any query, making the reasoning process both scalable and transparent. To save on costs, you can use a stronger model to generate the reasoning chains and a weaker model to generate the final answer.
How AutoReason Works
AutoReason is a 2-step, prompt only framework:
- Rationale Generation:
- A strong model generates step-by-step reasoning traces for a given query or task.
- These traces break down complex tasks into logical, interpretable steps
- Final Answer Generation:
- A cost-efficient model processes the query along with the generated reasoning traces to produce the final answer.

Here is the AutoReason template if you'd like to test it out.

AutoReason Performance
The researchers tested AutoReason across two datasets: StrategyQA and HotpotQA
HotpotQA

- AutoReason increases performance for GPT-3.5
- AutoReason degrades performance for GPT-4-Turbo
The reason why AutoReason performs worse with a more advanced model is because the questions in this dataset are relatively simple. Using a framework like AutoReason ends up confusing the model, which is why performance drops. This is very important to note because it is relevant for anyone writing promtps and using advanced models.
StrategyQA

- Since the questions in strategyQA are much more complex, AutoReason increases performance for both GPT-3.5, and GPT-4-Turbo
Automatically add Chain of Thought reasoning to your prompt
We recently launched prompt enhancers in PromptHub, including an option to generate chain of thought steps for any prompt. We took a look of inspiration from AutoReason when building this out. Feel free to try it out for free in PromptHub - it's available on all plans!

Difference Between Chain of Thought prompting and few-shot prompting
Not all few-shot prompts use Chain of Thought reasoning, and not all implementations of Chain of Thought use few-shot prompting.
For example, zero-shot Chain of Thought prompting, which we looked at above, is a Chain of Thought prompt that doesn’t use any examples. This version implements Chain of Thought prompting by adding a phrase like "let’s think step-by-step."
On the other hand, you can make a few-shot Chain of Thought prompt where you include questions and reasoning chains to help show the model a typical reasoning process.
Few-shot Chain of Thought prompts tend to outperform zero-shot Chain of Thought prompts. This is true for most types of prompts. Including examples via few-shot prompting is one of the best ways to enhance output quality.
Here is an example of a few-shot prompt that doesn’t use Chain of Thought reasoning.
Chain of Thought limitations
Chain of Thought is extremely powerful, but like all prompt engineering methods, it has limitations.
Model size requirement
In the original research paper, the researchers found that performance gains from Chain of Thought prompting only occurred once model sizes were in the ~100 billion parameter range. This is because Chain of Thought prompting is seen as an emergent behavior of model scale. As shown in the graph below, sharp vertical increases in performance, representing gains, only occur once the model scale reaches ~100 billion parameters.
The researchers also found that smaller-scale models were more likely to produce illogical yet coherent chains of reasoning, leading to performance that was lower than standard prompting.

Faithfulness and reliability
Sometimes the reasoning chains produced by Chain of Thought prompting don’t accurately represent how the model arrived at the answer. This can lead to a misleading interpretation of the model’s ‘thought process’.
As mentioned above, Faithful CoT is a nice tool to reach for if you’re worried about this problem.
Below is an example from a math dataset where the answer (in green) isn’t actually derived from the chain of reasoning (blue).
Prompt design and overfitting
Writing out effective Chain of Thought prompts can be complex and time-consuming. Additionally, as with any few-shot prompt, there is the risk of overfitting to specific types of examples, which can limit the model’s ability to generalize to new problems.
Methods like Auto-Chain of Thought prompting and Analogical prompting can help with these issues though!
Wrapping up
There’s a reason why Chain of Thought prompting is arguably the most well-known prompt engineering method: it’s simple, powerful, and versatile.
It can be implemented with just a few words, or via few-shot prompting with some examples. You can auto-generate the examples using Auto-CoT or Analogical prompting, or implement a different flavor of reasoning like Step-Back prompting.
The possibilities seem endless, which is great for anyone building on top of LLMs. There are so many ways to enhance reasoning to improve output quality.
So many possibilities can also feel overwhelming. If you have any questions on how to best implement chain of thought prompting, just let us know!





