
Prompt caching is one of the easiest ways to reduce costs and latency when prompting LLMs.
But each model provider handles prompt caching slightly differently. Navigating the intricacies of each provider is challenging, given that the information is usually spread across various pieces of documentation.
In a similar fashion to our model card directory, where we pulled info on various models and providers, this post aims to centralize prompt caching-related information for OpenAI, Anthropic, and Google models. Additionally, we’ll go over some high-level information and prompt caching best practices.
What is prompt caching
Prompt caching is an LLM feature that optimizes API requests by reusing parts of the prompt that remain consistent across multiple requests.
For example, if you have system instructions for a chatbot, rather than processing the same lengthy system message with each request, you can cache it and only process the new user messages, reducing costs and latency.
Prompt caching vs. classic caching
“Classic” caching usually refers to storing outputs for later use, like web pages or API results.
For example, apps often cache API responses that don't change frequently. Rather than requesting the same data over and over again, the data is stored in the cache so that subsequent requests can retrieve it without having to ping the API again.
Prompt caching is different in that it stores the static parts of the inputs. LLM outputs are dynamic and context-dependent, so it wouldn’t make sense to cache the output from a user's message. Instead, prompt caching stores the initial processing of the static parts of the input.
Why use prompt caching?
As prompts become larger and larger, cost and latency become issues. Additionally, prompt engineering methods like few-shot prompting and in-context learning make prompts longer as well.
By caching static portions of prompts, you get two main benefits:
- Reduced latency: Faster response times as the model skips reprocessing the cached parts of the prompt.
- Lower costs: Cached tokens are priced at a much cheaper rate.
How does prompt caching work?
At a high level, prompt caching works by identifying and storing the static portions of a prompt or array of messages. When a new request begins with the same exact prefix, meaning the exact same text, the model can leverage the cached computations for that initial section.
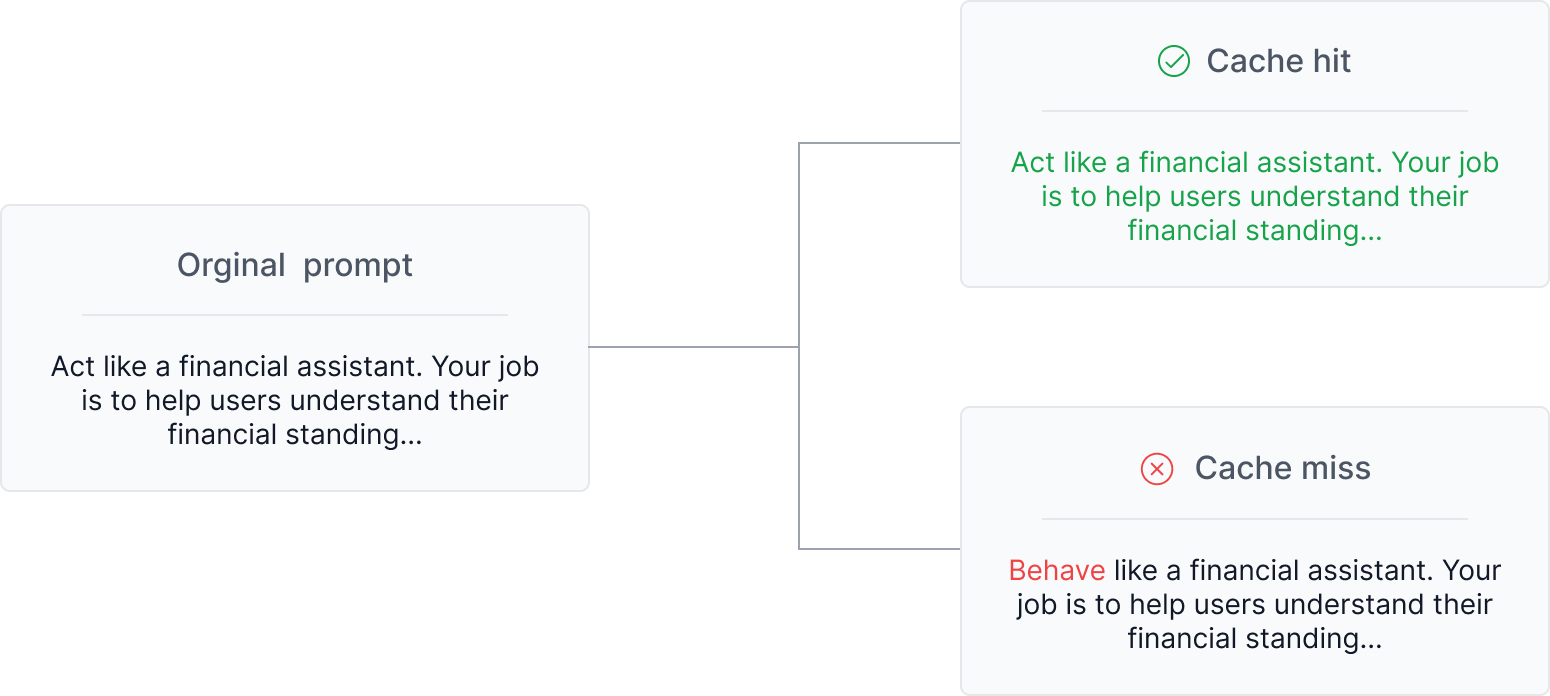
Generally, the prompt caching process involves a few steps:
- Tokenization: First, the model breaks down the prompt into tokens, which are the basic units the model understands. More on tokenization here: Tokens and Tokenization: Understanding Cost, Speed, and Limits with OpenAI's APIs
- Caching key-value pairs: During the initial processing, the model generates key-value pairs for these tokens. These intermediate representations are used in the self-attention mechanism of the model.
- Reusing cached data: For subsequent requests with the same prompt prefix, the model retrieves the cached key-value pairs, skipping the need to recompute them.
How prompt caching works, technically
Now let’s get slightly more technical.
Tokenization
Every interaction with an LLM starts with tokenization. Tokenization breaks the prompt into smaller units called tokens.

The self-attention mechanism
Transformer-based models, which are the foundation of most modern LLMs, use a mechanism called self-attention. This allows the model to consider the relationship between each token in the input sequence and every other token. During this process, the model generates three vectors for each token:
- Query (Q) vectors
- Key (K) vectors
- Value (V) vectors
These vectors are used to compute attention scores, which determine how much focus the model should place on each token when generating a response.
Caching key-value pairs
The core idea of prompt caching is to store the key and value vectors associated with the static parts of the prompt. Since these parts don't change across requests, their key-value (K-V) pairs stay consistent. By caching them:
- First request: The model processes the entire prompt, generating and storing the K-V pairs for the static sections.
- Subsequent requests: When the same prompt prefix is used, the model retrieves the cached K-V pairs, eliminating the need to recompute them.
Only the new, dynamic parts of the prompt (like the next user message) need processing.
Now we’ll look at how three of the major model providers, OpenAI, Anthropic, and Google, handle prompt caching.
Prompt caching with OpenAI
Compared to Anthropic and Google, OpenAI’s prompt caching is the most seamless, requiring no code changes.
How OpenAI’s prompt caching works
- Automatic caching: Prompt caching is enabled for prompts that are 1,024 tokens or longer, with cache hits occurring in increments of 128 tokens.
- Cache lookup: When a request is made, the system checks if the initial portion (prefix) of your prompt is stored in the cache. This happens automatically.
- Cache hits and misses:
- Cache hit: If a matching prefix is found, the system uses the cached result, decreasing latency by up to 80% and cutting costs by up to 50%.
- Cache miss: If no matching prefix is found, the system processes the full prompt and caches the prefix for future requests.
- Cache lifespan: Cached prefixes remain active for 5 to 10 minutes of inactivity. During off-peak periods, caches may persist for up to one hour. However, all entries are evicted after one hour, even if they are actively used.
- What can be cached: The complete messages array, images (links or base64-encoded data), tools, and structured outputs (output schema).
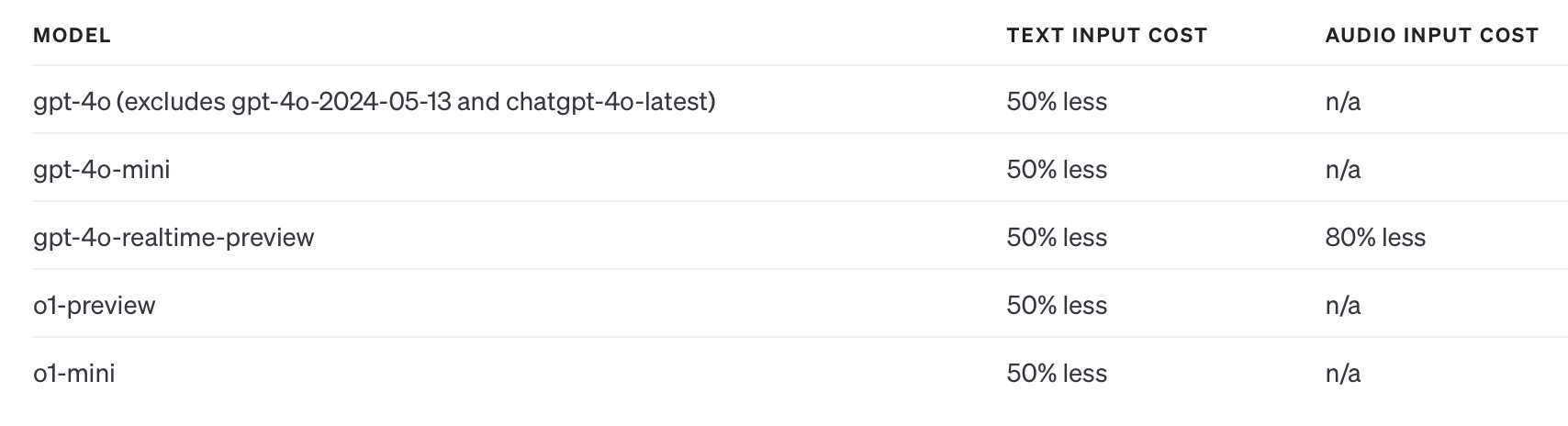
- Supported models: Gpt-4o, gpt-4o-mini, gpt-4o-realtime-preview, o1-preview, o1-mini
Monitoring usage details
In order to see if you are getting a cache hit you can check out the usage field in the API response to see how many tokens were cached.
{
"prompt_tokens": 1200,
"completion_tokens": 200,
"total_tokens": 1400,
"prompt_tokens_details": {
"cached_tokens": 1024
}
}cached_tokens shows how many tokens were retrieved from the cache.
Pricing
Prompt caching can reduce input token cost by 50%. This reduction is applied automatically whenever a cache hit occurs.
Example
# Static content placed at the beginning of the prompt
system_prompt = """You are an expert assistant that provides detailed explanations on various topics.
Please ensure all responses are accurate and comprehensive.
"""
# Variable content placed at the end
user_prompt = "Can you explain the theory of relativity?"
# Combine the prompts
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]In this example we place the static system prompt at the beginning, and the dynamic user message afterwards. This setup increases the likelihood of cache hits.
FAQs
- Data privacy: Prompt caches are stored at the organization level, meaning they are not shared between different organizations.
- Impact on output: Prompt caching does not affect the generation of output tokens or the final response provided by the API.
- Manual cache clearing: Currently, it is not possible to clear the cache manually.
- Costs: Caching happens automatically and there is no extra cost. You just pay for the tokens used, as you normally would.
- Rate limits: Cached prompts contribute to tokens per minute (TPM) rate limits.
Prompt caching with Anthropic’s Claude
Anthropic’s prompt caching features offers more control, but requires code changes to cache specific parts of a prompt using the cache_control parameter.
How Anthropic’s prompt caching works
- Enabling prompt caching: Add the header
anthropic-beta: prompt-caching-2024-07-31in your API requests to enable prompt caching. - Manual configuration: Use the
cache_controlparameter to mark parts of your prompt for caching. - Cache breakpoints: You can define up to four cache breakpoints in a single prompt, allowing separate reusable sections to be cached independently.
- Cache reference order: Caches are processed in the order of
tools,system, and thenmessages. - Cache lifespan: The cache has a 5-minute Time to Live (TTL), which refreshes each time the cached content is used.
- Monitoring cache performance: Analyze caching efficiency via the
cache_creation_input_tokens,cache_read_input_tokens, andinput_tokensfields in the API response. - Supported models: Prompt caching is available for Claude 3.5 Sonnet, Claude 3 Opus, Claude 3 Haiku, and Claude 3.5 Haiku.
Pricing
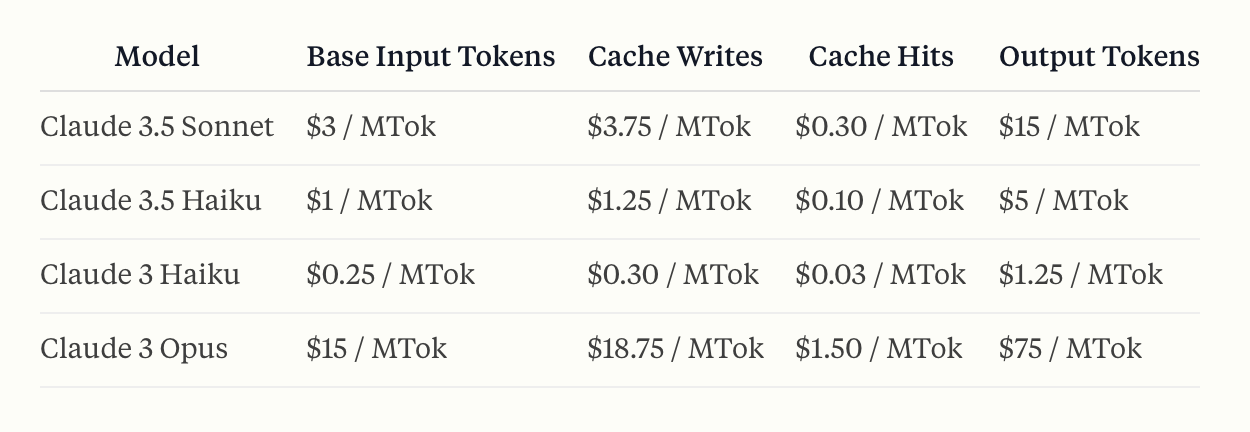
- Cache write Cost: Writing tokens to the cache costs 25% more than the base token price.
- Cache read discount: Reading tokens from the cache is 90% cheaper than normal token processing.
- Overall savings: Despite the higher cost of cache writes, the significant discount on reads should result in large cost savings.
Examples
Example 1: Caching a large document.
# Static content: System prompt and large document
system_prompt = {
"type": "text",
"text": "You are an AI assistant tasked with analyzing private equity documents."
}
large_document = {
"type": "text",
"text": "Full text of a complex private equity agreement: [Insert 50-page M&A document here]",
"cache_control": {"type": "ephemeral"}
}
# Variable content: User's question
user_message = {
"role": "user",
"content": "What are the key terms and conditions in this agreement?"
}
response = client.completion(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
headers={
"anthropic-beta": "prompt-caching-2024-07-31"
},
system=[system_prompt, large_document],
messages=[user_message]
)
print(response['completion'])
cache_control: Thelarge_documentis marked for caching using thecache_controlparameter.- Prompt structure: Static content (system prompt and large document) is placed at the beginning, while variable content follows and is not cached.
Example 2: Caching tools
tools = [
{
"name": "get_weather",
"description": "Get the current weather in a location",
"input_schema": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g., San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The unit of temperature, either celsius or fahrenheit"
}
},
"required": ["location"]
},
"cache_control": {"type": "ephemeral"}
}
],
response = client.completion(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
headers={
"anthropic-beta": "prompt-caching-2024-07-31"
},
tools=tools,
messages=[
{
"role": "user",
"content": "What is the weather and time in New York?"
}
]
)
print(response['completion'])
- Caching tools: Tools are included in the cache, allowing reusable functionality across multiple requests.
- Variable content: User queries can change, leveraging cached tools for efficiency.
Example 3: Caching a large system message
{
"model": "claude-3-opus-20240229",
"max_tokens": 1024,
"system": [
{
"type": "text",
"text": "You are a pirate, talk like it. Lorem ipsum odor amet...",
"cache_control": {"type": "ephemeral"}
}
],
"messages": [
{"role": "user", "content": "whats the weather"}
]
}
FAQs
- Cache lifetime: The cache TTL is 5 minutes, refreshed on each use.
- Ephemeral cache: Currently, the only cache type available is ephemeral, limited to a 5-minute lifespan. Future cache types may offer longer durations.
- Cache breakpoints: Up to four cache breakpoints can be defined within a prompt.
- Data privacy: Prompt caches are isolated at the organization level, ensuring that different organizations cannot access each other's caches.
Context caching with Google’s Gemini
Google calls it “context caching”. Their offering is more confusing, and more customizable, with options to set the cache duration and manually create the cache (similar to Anthropic).
How context caching with Gemini works
- Cache creation: Use the
CachedContent.createmethod to create a cache with the desired content and Time to Live (TTL). - Including cache in requests: Include the cache when defining the model with the
GenerativeModel.from_cached_contentmethod. - Cache lifespan: The default TTL is 1 hour, but developers can specify a custom TTL (note that longer TTLs incur additional costs).
- Monitoring cache performance: Use the
response.usage_metadatafield to track cached token usage and analyze costs. - Supported models: Context caching is available on stable versions of Gemini 1.5 Flash (e.g.,
gemini-1.5-flash-001) and Gemini 1.5 Pro (e.g.,gemini-1.5-pro-001).
Pricing
Google's pricing model for context caching is more complex, here is a resource that provides some additional examples: Google's documentation on pricing
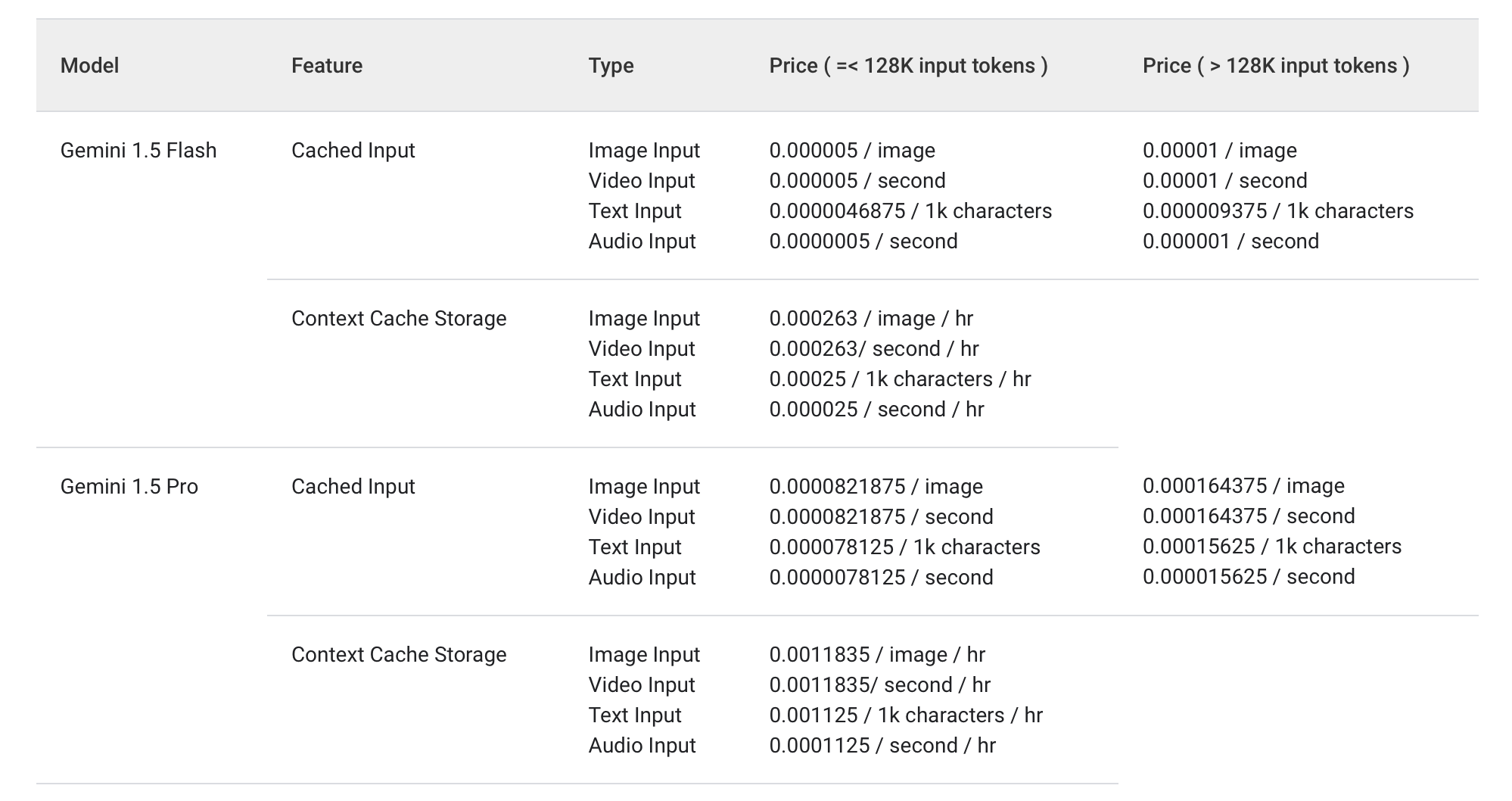
- Cache creation cost: There is no additional charge for creating a cache itself.
- Cache storage cost: Additional charges based on the number of cached tokens and the TTL (token-hours).
- Cache read discount: Reading tokens from the cache costs 75% less than processing non-cached input tokens.
Example cost calculation
Let’s calculate costs for a prompt caching scenario with the following assumptions where we have an initial prompt of 100,000 tokens and we want a TTL of 1 hours.
Cache creation:
- Input tokens: 100,000 tokens.
- Gemini 1.5 Pro input token pricing: $0.0003125 per 1,000 tokens.
- Cost: 100,000 tokens × ($0.0003125 per 1,000 tokens) = $0.03125.
Cache storage:
- Total token-hours: 100,000 tokens × 1 hour TTL = 100,000 token-hours.
- Cost: 100,000 token-hours × ($0.001125 per 1,000 token-hours) = $0.1125.
Requests using cache:
- Input tokens per request (non-cached): 150 tokens.
- Number of requests: 10.
- Total non-cached input: 150 tokens × 10 = 1,500 tokens.
- Cost for non-cached input: 1,500 tokens × ($0.0003125 per 1,000 tokens) = $0.00046875.
- Cached input tokens per request: 100,000 tokens.
- Total cached input: 100,000 tokens × 10 = 1,000,000 tokens.
- Cost for cached input: 1,000,000 tokens × ($0.000078125 per 1,000 tokens) = $0.078125.
Output tokens:
- Output tokens per request: 500 tokens.
- Total output tokens: 500 tokens × 10 = 5,000 tokens.
- Cost for output tokens: 5,000 tokens × ($0.00375 per 1,000 tokens) = $0.01875.
Total cost:
- Cache creation: $0.03125.
- Cache storage: $0.1125.
- Input costs: $0.00046875 (non-cached) + $0.078125 (cached) = $0.07859375.
- Output costs: $0.01875.
- Grand total: $0.03125 (cache creation) + $0.1125 (cache storage) + $0.07859375 (input costs) + $0.01875 (output costs) = $0.24009375.
Cost without caching:
Processing the full prompt (100,150 tokens) for each of the 10 requests without caching would cost:
- Total input tokens: 100,150 tokens × 10 = 1,001,500 tokens.
- Input cost: 1,001,500 tokens × ($0.0003125 per 1,000 tokens) = $0.31321875.
- Total output tokens: 500 tokens × 10 = 5,000 tokens.
- Output cost: 5,000 tokens × ($0.00375 per 1,000 tokens) = $0.01875.
- Grand total without caching: $0.31321875 (input cost) + $0.01875 (output cost) = $0.33196875.
Savings with caching:
- Total savings: $0.33196875 (without caching) - $0.24009375 (with caching) = $0.091875. A savings of roughly 27%
Example
Creating and using a cache
# Create a cache with a 10-minute TTL
cache = caching.CachedContent.create(
model='models/gemini-1.5-pro-001',
display_name='Legal Document Review Cache',
system_instruction='You are a legal expert specializing in contract analysis.',
contents=['This is the full text of a 30-page legal contract.'],
ttl=datetime.timedelta(minutes=10),
)
# Construct a GenerativeModel using the created cache
model = genai.GenerativeModel.from_cached_content(cached_content=cache)
# Query the model
response = model.generate_content([
'Highlight the key obligations and penalties outlined in this contract.'
])
print(response.text)
- Cache creation: The
CachedContent.createmethod creates a cache for static content (e.g., a video transcript). - TTL specification: A 5-minute TTL is applied.
- Using the cache: The
GenerativeModel.from_cached_contentmethod includes the cache in the model definition. - Making queries: Subsequent requests can leverage the cached content.
Comparing prompt caching across model providers
Pulling the most important metrics together, here’s a helpful table to compare at-a-glance.
| Feature |
|
|
|
|---|---|---|---|
| Activation | Automatic | Manual via API configuration and cache creation | Manual via cache creation |
| Cost Savings | Up to 50% discount on cache hits | 90% discount on cache reads | 75% discount on cache reads |
| Cache Write Cost | No extra cost | 25% surcharge | Standard input cost |
| Cache Duration (TTL) | 5-10 min (up to 1 hr off-peak) | 5 min (refreshed on access) | Default 1 hr (customizable) |
| Minimum Prompt Length | 1,024 tokens | 1,024 (Claude 3.5 Sonnet and Claude Opus) or 2,048 tokens (Claude 3.5 Haiku and Claude 3 Haiku) | 32,768 tokens |
| Best For | General use | Large, static data | Large contexts with extended TTL |
| Track Cache Performance | Check prompt_tokens_details.cached_tokens | cache_creation_input_tokens and cache_read_input_tokens | usage_metadata |
Best practices for effective prompt caching
Prompt caching can be an easy way to increase speed and decrease latency when implemented correctly. Here are some best practices to help you maximize the benefits of prompt caching regardless of which LLM provider you are using.
Structure your prompts effectively
- Static content should be at the beginning of the request: Include system instructions, contextual information, and few-shot examples.
- Dynamic content should be at the end of the request: This includes user messages or other variable inputs.
- Use clear separators: Consistently use markers (e.g.,
###, ``) to divide static and dynamic content. Maintain uniformity in whitespace, line breaks, and capitalization to enhance clarity and improve cache recognition. - Ensure exact Matches: Cache hits depend on exact matching of content, including formatting. Carefully review prompts to ensure accuracy and consistency.
Here is an example of how this could look:
[Static Content - Cacheable]
- System Instructions: Detailed guidelines for the AI model.
- Contextual Information: Background data, articles, or documents.
- Examples: Sample inputs and desired outputs.
###
[Dynamic Content - Non-cacheable]
- User Question or Input: The specific query or task from the user.
Track cache performance metrics
Each model provider handles it differently, but tracking cache performance is important to make sure you are getting maximum savings and latency gains.
- API Response Fields:
- OpenAI: Check
prompt_tokens_details.cached_tokens - Anthropic's Claude:
cache_creation_input_tokensandcache_read_input_tokens. - Google's Gemini:
usage_metadata
- OpenAI: Check
Real-world prompt cache examples
Here are a few more real-world examples of how you might use prompt caching.
Customer support chatbot
- Challenge: A customer support chatbot needed to provide quick responses, while accessing a large knowledge base.
- Solution:
- Cached the knowledge base: Send the static knowledge base info in the system message to have it live in the cache.
- Structured prompts effectively: Place user queries after the system message.
- Result: After the initial request, the model will respond faster and with lower costs since fewer tokens being processed per request.
A coding assistant
- Challenge: A coding assistant needs frequent access to documentation and code libraries.
- Solution:
- Cached documentation: Store frequently used documentation snippets in the cache.
- Minimized cache invalidations: Ensured code examples remained consistent.
- Result: Improved efficiency and user experience with faster code suggestions and explanations.
Wrapping up
Prompt caching is one of my favorite new features from the major model providers. By enabling the reuse of static parts of prompts, it reduces latency, lowers costs, and improves user experience (via faster responses).
Even though normal token costs continue to drop, the value in the reduced latency is reason enough to give it a try.





