
A very common question we’ve been hearing since the launch of o1-preview is, “When should I use a reasoning model like o1-preview versus GPT-4o?” It’s a great question—and one we’ve been thinking about a lot. Both models have their strengths, but when is it best to choose one over the other?
At first, I thought it was a simple decision: go for the reasoning model for anything complex, and use the non-reasoning model for the basics. But even that raises questions: how do you determine whether a task is 'complex enough' to warrant calling in the big guns of a reasoning model? As I dug deeper into the latest research, it became clear that the decision is far more nuanced.
On top of the decision of which model to use is also the question of how to structure the prompts for each model. Do they need to be different? If so, how different?
Luckily, there has been a flurry of recent papers to help answer these questions. In this post, we’ll dive into the research to clarify when and how prompt engineering should differ for reasoning versus non-reasoning models.
We’ll explore which model performs best on certain tasks, when you can skip advanced prompting, and best practices for prompt engineering with reasoning models. We'll also touch on the recent release of DeepSeek's R-1 model and how their findings relate to prompt engineering.
By the end, you’ll have a clear guide to choosing the right model and prompting strategy to get the most out of each approach.
Prompt engineering with reasoning vs. non-reasoning models
First up, we’ll see how different prompt engineering methods affect reasoning models, like o1-preview, versus non-reasoning models like GPT-4, GPT-4o, Claude 3.5 Sonnet, and more.
To quickly level set, here are the prompt engineering techniques that we’ll be looking at throughout the post:
- Zero-Shot Prompting: Just a simple prompt containing instructions.
- Few-Shot Prompting: A prompt that includes a few examples to help guide the response.
- Chain-of-Thought (CoT) Prompting: A prompt that instructs the model to do some reasoning before giving an answer.
- Task-Specific and Critique Prompting: Custom prompts created for a specific task or to critique and refine responses.
This brings us to our first paper, Do Advanced Language Models Eliminate the Need for Prompt Engineering in Software Engineering?
This paper specifically analyzed the effect of prompt engineering methods on GPT-4o and o1-mini across three code-related tasks: Code generation, code translation and code summarization.
The paper set out to determine if prompt engineering techniques that worked for earlier LLMs still work for the newer reasoning models.
Experiments and Methods
- Code Generation: The models were tasked with generating accurate, functional code snippets based on input descriptions.
- Code Translation: Here, the models were asked to translate code from one programming language to another.
- Code Summarization: The task required models to create concise summaries of code functions.
The researchers measured accuracy and resource use.
Results
Let’s look at some data.
First up is a table of results comparing different prompt engineering methods on the code generation task.
Since OpenAI restrains o1-mini from generating a chain of thought, the researchers incorporated the chain of thought generated by GPT-4o as part of the input prompt for o1-mini.
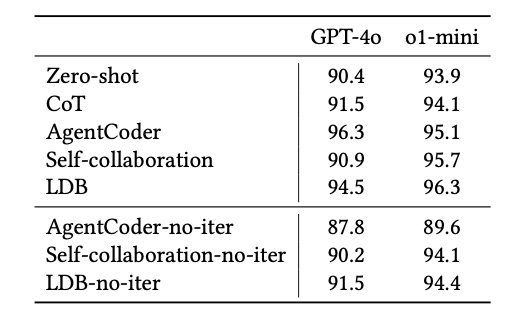
- Overall, most of the prompt engineering methods help boost performance for GPT-4o.
- Chain-of-Thought (CoT) prompting provides a small additional boost in certain cases, but the effect is minimal.
- Fewer prompt engineering methods result in a performance boost for o1-mini, and the margin of improvement is even smaller.
Next we’ll look at the results for the code summarization task.
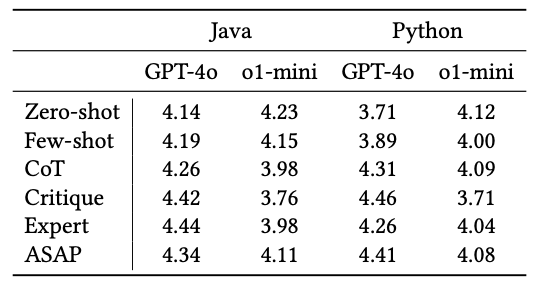
- For GPT-4o, all prompt engineering methods outperform zero-shot prompting
- For o1-mini, many prompt engineering methods actually result in worse performance.
- o1-mini's performance decreases when using CoT prompts, signaling that those types of instructions are unnecessary given its built in reasoning
Lastly, the code translation task.
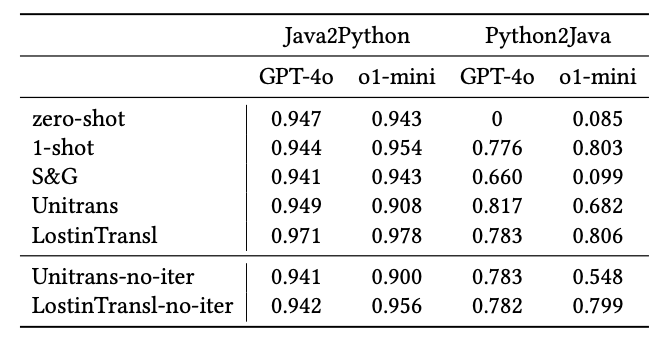
- Prompt engineering methods continue to show limited impact on o1-mini's performance.
- With prompt engineering methods, GPT-4o can often rise to or exceed o1-mini’s performance level
Takeaways
Specifically in relation to the effect of prompt engineering methods on the two models, here’s the TL;DR:
- GPT-4o: Benefited from traditional prompt engineering techniques. Few-shot and CoT prompting led to some performance improvements, particularly in code generation and summarization. Was able to achieve o1-mini like performance with the right prompt engineering methods.
- o1-mini: The built-in reasoning capabilities made simple zero-shot prompts as effective, if not more effective, than some of the more complex prompt engineering methods (especially on code translation).
Continuing on this question of the effectiveness of prompt engineering methods for reasoning versus non-reasoning models, we’ll turn to our next paper: From Medprompt to o1: Exploration of Run-Time Strategies for Medical Challenge Problems and Beyond. This is an update to an original paper we covered last year: Prompt Engineering vs. Fine-Tuning: The MedPrompt Breakthrough
The paper focused on developing a prompt engineering framework called Medprompt, designed to outperform fine-tuned models on medical datasets for medical tasks. Originally, Medprompt was tested with GPT-4, but in this new version, the researchers tested GPT-4o and o1-preview.
Medprompt consists of three core components: few-shot prompting, automatic chain-of-thought (CoT), and ensembling.
Below is a snapshot of the performance gains, based on the different prompt engineering methods used.


Let’s dive into some graphs.

This graph shows the test accuracy of different models over time. You can see that o1-preview, without the Medprompt framework, outperforms GPT-4 with the Medprompt framework.

- Overall, the results show that o1-preview with zero-shot prompting frequently outperforms GPT-4 models using the Medprompt framework.
- This reinforces the idea that specific prompting techniques are less impactful for o1 models but remain valuable tools for GPT-4-level models.
Next is my favorite graph from the study. The researchers isolated and compared the individual impact of the prompt engineering methods used in Medprompt when using o1-preview.

Most notably, five-shot prompting leads to a significant decrease in performance! This is my first time seeing data like this, but it aligns with guidance from OpenAI that notes that excessive retrieved context results in worse performance. As OpenAI explains in their documentation:
“Limit additional context in retrieval-augmented generation (RAG): When providing additional context or documents, include only the most relevant information to prevent the model from overcomplicating its response.”
For reference, here is the few-shot prompt template used.
Next up was testing a tailored prompt and ensembling.
Here is the tailored prompt template:

- Minimal gains for a tailored prompt versus the basic one (See templates above)
- Ensembling did improve performance, but it also required 15 API calls
- Few-shot prompting consistently hurt performance
One last interesting finding in relation to prompting with reasoning models.
The graph below compares two prompts templates and their performance. One template asks for a quick response, and the other instructs the model to respond with more reasoning.

Here are the two prompt templates:
1. Prompt that elicits the model to respond with less reasoning and completion token
2. Prompt that elicits the model to respond with more reasoning and completion tokens.
As you can see in the graph, the extended reasoning prompt leads to more reasoning and completion tokens, which results in higher performance. It appears there is a correlation between reasoning tokens and performance. The more reasoning tokens, the better the performance. OpenAI noted this as well in their blog post that announced o1-preview:
“We have found that the performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute”
Last up is a nice heatmap that ties it all together.

The heatmap shows absolute accuracy and relative performance over the zero-shot prompt baseline, across all benchmarks.
Takeaways
- Few-shot prompting reduced performance for the reasoning model. It seems that the additional context can overwhelm the model’s reasoning capabilities
- The reasoning model consistently performed best with minimal prompting
- For models like GPT-4o, detailed and specific prompts can still boost performance.
- Ensembling boosted performance for both models, but only by a small margin for o1-preview
The last paper we'll look at is the R-1 paper from DeepSeek.
We did a deep dive on the training process and performance of the modal against other reasoning models like OpenAI's o1 and o1-mini. For this guide, we'll focus mostly on the prompt engineering findings.
Firstly, if you want to check out the prompt template they used to train their model to generate reasoning chains, here is the link.

As noted in the MedPrompt paper, the researchers also found that the longer the response, the better the output.

Additionally, they also found that few-shot prompting lead to worse performance! This is another crucial datapoint for this idea.
Prompting Engineering: When evaluating DeepSeek-R1, we observe that it is sensitive to prompts. Few-shot prompting consistently degrades its performance. Therefore, we recommend users directly describe the problem and specify the output format using a zero-shot setting for optimal results.
When to use reasoning versus non-reasoning models
Choosing the right model for a given task can feel more like art than science. There are multiple factors to consider, such as cost, performance, and latency. Luckily the latest research helps us get a better sense of when to use a reasoning model or not.
Performance
For problems that involve multiple steps of reasoning, reasoning models like o1-mini are typically a better fit.
An analysis from the paper Do Advanced Language Models Eliminate the Need for Prompt Engineering in Software Engineering? found that when the CoT length is five steps or more, o1-mini outperforms non-reasoning models like GPT-4o by an average of 16.67% (on code generation tasks). For tasks with CoT lengths under five steps, o1-mini’s advantage drops to just 2.89%. In simpler tasks with fewer than three steps, o1-mini underperformed GPT-4o in 24% of cases due to unnecessary, expansive reasoning.
To determine the CoT length of a problem, you can test the prompt in ChatGPT using a reasoning model and see how many reasoning steps it generates.
The researchers also found that o1-mini frequently failed to adhere to expected output formats. Nearly 40% of its outputs did not match fixed code segments, requiring additional post-processing, while GPT-4o consistently delivered correct formats.
Similarly, in summarization tasks, o1-mini’s responses often included descriptions of its reasoning instead of concise answers, requiring further processing. In contrast, GPT-4o provided clear and concise answers, without reasoning steps.
To put it briefly, GPT-4o is the better choice for tasks requiring fewer than five CoT steps or where concise, well-structured outputs are critical. For tasks involving more than five CoT steps, reasoning models are the way to go.
Cost and latency
Currently the reasoning models are much more expensive than GPT-4o. You can check out the costs for the models, and others in our model card directory. In the experiments above, we've seen that through certain prompt engineering methods, it is possible to get o1 level performance out of GPT-4o. It really comes down to your use case and token budget.
Performance comparison on specific tasks
To continue to add context around how reasoning and non-reasoning models perform across tasks, we’ll turn to three papers that benchmarked these models across a few tasks
1. Spider 2.0 (Text-to-SQL Workflow)
Overview
The Spider 2.0 evaluated models in text-to-SQL workflows, where models were tasked with translating natural language queries into SQL commands. These tasks ranged from simple single-step queries to complex, multi-step logical sequences, assessing each model’s ability to handle structured data manipulation.

Model Performance:
- Reasoning Model (o1-preview): o1-preview performed best on more complex SQL generation tasks, achieving the highest success rate of 17.01%. Its built-in reasoning allowed it to handle multi-step logic in layered queries more effectively.
- Non-Reasoning Models (GPT-4o and Claude 3.5 Sonnet): GPT-4o and Claude-3.5-Sonnet showed solid performance on simpler, single-step SQL tasks, especially when enhanced with task-specific prompts. But they both struggled on more complex cases, that required longer chains of reasoning.
Takeaways
For complex SQL workflows that require multi-step reasoning, reasoning models like o1-preview are clearly better. GPT-4o can easily handle straightforward SQL tasks when paired with tailored prompts.
2. Evaluating the Accuracy of Chatbots in Financial Literature Tasks
Overview
I loved this paper. It evaluated how well models like o1-preview and GPT-4o handled tasks involving factual accuracy in financial literature, specifically looking at hallucination rates when generating citations.

Model Performance
- Reasoning Model (o1-preview): o1-preview’s hallucination rate was 21.3%, slightly higher than GPT-4o’s rate.
- GPT-4o: GPT-4o’s rate was slightly lower at 20.0%
- Gemini Advanced (which is Gemini 1.5 Pro): Shocked to see Gemini's hallucination rate was 76.7%. More then 3x higher than both of the OpenAI models
Takeaways
I was surprised to see that the hallucination rates were essentially equivalent across GPT-4o and o1-preview. Since GPT-4o is cheaper and faster, it may be the better choice where you’re generating citations.
3. Mind Your Step (BY STEP): Chain-of-Thought Can Reduce Performance on Certain Tasks
Overview
The Mind Your Step paper looked into tasks where Chain-of-Thought (CoT) prompting actually reduced performance. By evaluating models on tasks like artificial grammar learning and facial recognition, the study identified scenarios where reasoning steps can overcomplicate otherwise straightforward problems.
Below are a few tables of data from the different tasks.




Here were the prompt templates used:
The only difference is in the last line of text.
Model Performance
- Reasoning Model (o1-preview): While o1-preview has built-in CoT capabilities, the study found that CoT prompting led to a 36.3% drop in performance on simple tasks, where excessive reasoning confused the model.
- Non-Reasoning Model: GPT-4o, when used without CoT prompting, maintained stable performance on these simple tasks, outperforming reasoning models in accuracy by following straightforward instructions. Without unnecessary reasoning steps, GPT-4o performed better on tasks requiring direct answers.
Takeaways
For simple tasks (see section above on when to use reasoning models) where reasoning could introduce unnecessary complexity, non-reasoning models like GPT-4o are often the better choice. These tasks benefit from direct, zero-shot prompting, highlighting that CoT isn’t universally effective and may reduce performance in scenarios where reasoning isn’t required.
Best practices when using reasoning models
Bringing it all together, here are the current best practices.
- Use minimal prompting for complex tasks: Rely on zero-shot or single-instruction prompts and let the model’s internal reasoning do its thing.
- Encourage more reasoning for complex tasks: Explicitly instruct the model to spend more time reasoning for really complex tasks. OpenAI’s guidance and experiments from the Medprompt paper show that increasing reasoning tokens leads to improved performance.
- Avoid few-shot prompting: Either skip few-shot prompts or include only one or two, and make sure you test extensively
- Limit Chain-of-Thought (CoT) steps in simple tasks: Avoid CoT prompts for straightforward tasks to prevent overthinking and ensure accuracy. See "Quick Response" template from the Medprompt paper.
- Leverage built-in reasoning for multi-step challenges: Use reasoning models for tasks requiring five or more CoT steps, where they outperform non-reasoning models.
- Address output consistency with structured prompts: Keep prompts clear and concise to maintain formatting, particularly in code generation or structured tasks.
- Apply ensembling for high-stakes tasks: Run multiple iterations and select the most consistent output to increase reliability in critical tasks (assuming cost and latency aren't an issue).
- Weigh cost and latency considerations carefully: Opt for non-reasoning models in simpler tasks to save on budget and latency.
Conclusion
Reasoning models are brand new, so I expect more research to come out, but we have enough information to start to make some informed decisions already. Have any questions? Feel free to reach out!





