
Integrating PromptHub with Amazon Bedrock makes it easy to enable collaboration on prompts while using models hosted in Bedrock.
In this guide, we’ll walk through the process of setting up an integration between PromptHub and Amazon Bedrock. By the end, you’ll know how to:
- Retrieve prompts from PromptHub’s Get a Project’s Head (/head) endpoint and dynamically update the variables with data from your application
- Execute prompts that live in PromptHub using your models in Bedrock using the Run a Project (/run) endpoint
- Replace variables with dynamic content to create fully formatted prompts.
- Send prompts to models in Amazon Bedrock using its runtime API.
This guide is for anyone integrating PromptHub with models in AWS Bedrock.
Before we jump in, here are a few resources you may want to open in separate tabs.
- PromptHub: PromptHub documentation
- AWS: How to invoke a model in Bedrock at runtime
- AWS: Invoke Anthropic Claude models on Amazon Bedrock using the Invoke Model API with a response stream
- AWS: AWS code example repos on Github for Bedrock runtime
Setup
Here’s what you’ll need to integrate PromptHub with Amazon Bedrock and test locally:
- Accounts and credentials:
- A PromptHub account: Sign up here if you don’t have an account yet (it’s free)
- PromptHub API key: Generate this in your account settings under "API Keys". Click your avatar and it’s towards the bottom of the navigation panel.
- An AWS account with access to Amazon Bedrock.
- AWS credentials configured in your local environment
- Installed tools:
- Python
- Required Python libraries:
requestsandboto3.
- Project setup:
- Create a project in PromptHub and commit an initial version. Feel free to try out using our Prompt Generator to get a high-quality prompt, fast!
- For this guide, we’ll use the following example project which has a system message, and a prompt with one variable:
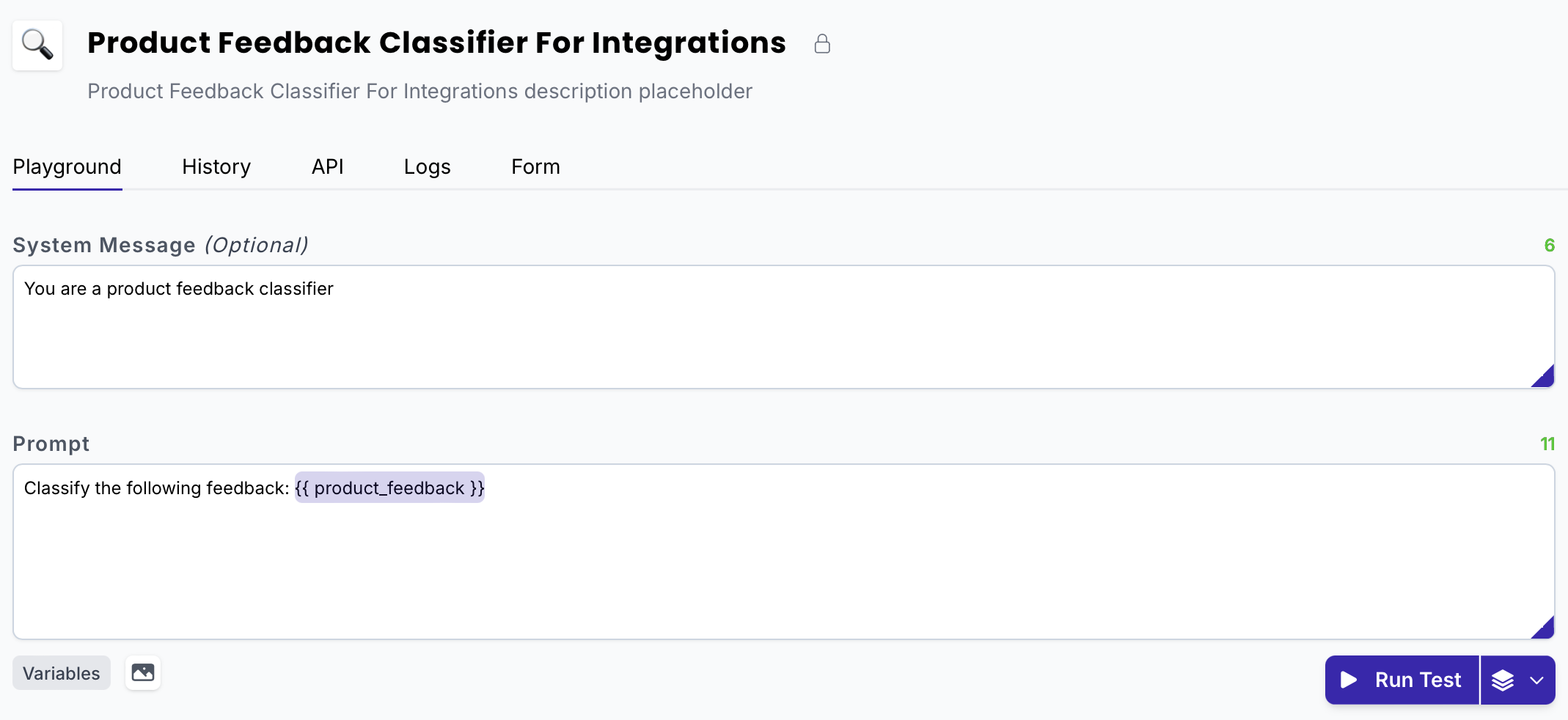
System message
You are a product feedback classifier
Prompt
Classify the following feedback: {{product_feedback}}
Retrieving a prompt from PromptHub
Now that you’ve created a project and committed a prompt version, the next step is to retrieve the prompt using the /head endpoint. This will fetch the latest version of the prompt.
You’ll need the project ID to retrieve the prompt. You can find it in the URL bar when viewing a project in the dashboard or under the API tab, where the full request URL containing the project ID is shown.
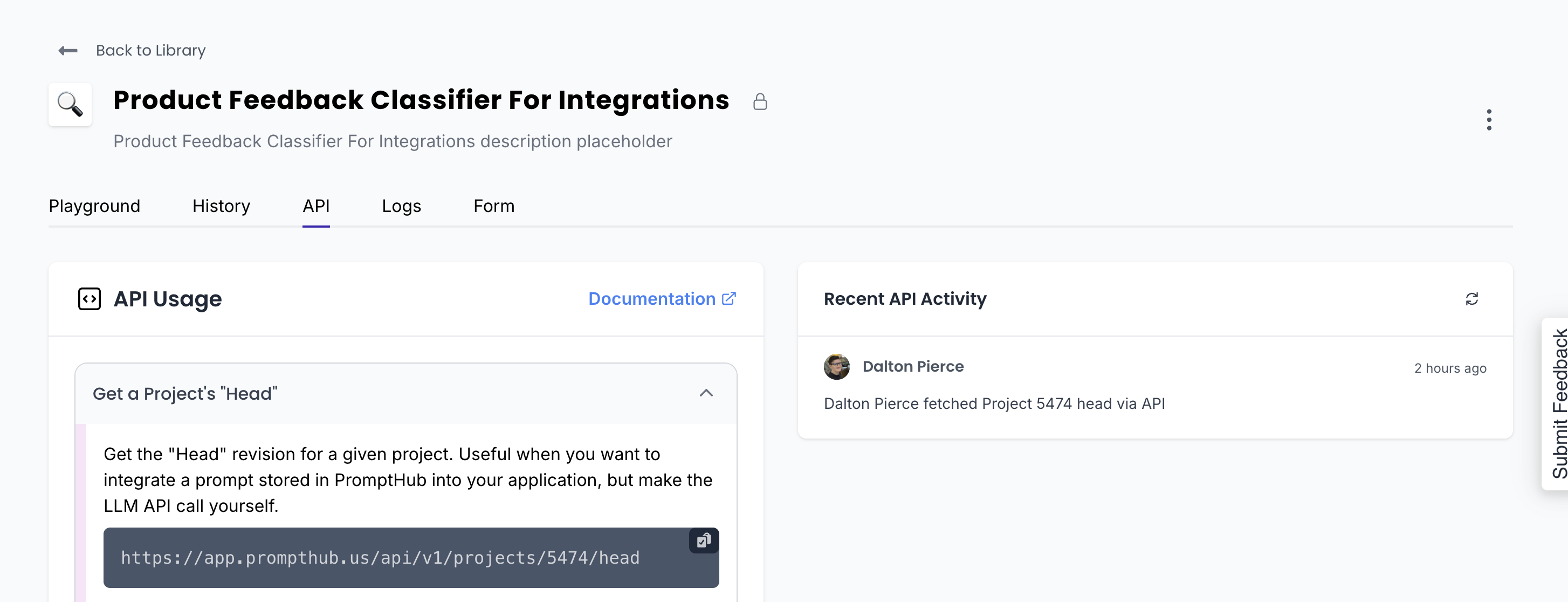
The response from this endpoint has a few important values, which we'll use in the next steps:
formatted_request: An object that is structured to be sent to a model (GPT-4o, Claude 3.5 Sonnet, etc) . We format it for you so all you need to do is send it to your LLM provider. For example:Model: The model you set when committing a version in PromptHubSystem message: The text of your system messagePrompt: The text of your promptMax_tokens, temperature, etc: Any parameters you set in the PromptHub playground likemax_tokens,temperature, ortop_p.
- Variables: A dictionary of the variables used in the prompt and system message, plus the value used in PromptHub. You will need to replace these variables with data from your application (more on this below).
Here is the output from hitting this endpoint for our example feedback classifier:
{
"data": {
"id": 11917,
"project_id": 5474,
"user_id": 5,
"branch_id": 8488,
"provider": "Amazon",
"model": "us.anthropic.claude-3-5-sonnet-20241022-v2:0",
"prompt": "Classify the following feedback: {{ product_feedback }}",
"system_message": "You are a product feedback classifier",
"formatted_request": {
"model": "us.anthropic.claude-3-5-sonnet-20241022-v2:0",
"system": "You are a product feedback classifier",
"messages": [
{
"role": "user",
"content": "Classify the following feedback: {{ product_feedback }}"
}
],
"max_tokens": 8192,
"temperature": 0.5,
"top_p": 1,
"stream": false
},
"hash": "2852210e",
"commit_title": "First commit",
"commit_description": "First commit",
"prompt_tokens": 12,
"system_message_tokens": 7,
"created_at": "2025-01-06T14:23:01+00:00",
"variables": {
"system_message": [],
"prompt": {
"product_feedback": "the product is great!"
}
},
"project": {
"id": 5474,
"type": "completion",
"name": "Product Feedback Classifier For Integrations",
"description": "Product Feedback Classifier For Integrations description placeholder",
"groups": []
},
"branch": {
"id": 8488,
"name": "master",
"protected": true
},
"configuration": {
"id": 1240,
"max_tokens": 8192,
"temperature": 0.5,
"top_p": 1,
"top_k": null,
"presence_penalty": 0,
"frequency_penalty": 0,
"stop_sequences": null
},
"media": [],
"tools": []
},
"status": "OK",
"code": 200
}
Here is a shortened version that has the fields we are most concerned about:
{
"data": {
"formatted_request": {
"model": "us.anthropic.claude-3-5-sonnet-20241022-v2:0",
"system": "You are a product feedback classifier",
"messages": [
{
"role": "user",
"content": "Classify the following feedback: {{ product_feedback }}"
}
],
"max_tokens": 8192,
"temperature": 0.5,
"top_p": 1,
"stream": false
},
"variables": {
"product_feedback": "The product is great!"
}
},
"status": "OK",
"code": 200
}
All this data comes from the configuration you set when committing a prompt in PromptHub. We version not only the text of the prompt and system message but also the model configuration.
Now that we understand the output shape, here’s a Python script to retrieve the prompt:
import requests
url = 'https://app.prompthub.us/api/v1/projects/5474/head?branch=master'
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json',
'Authorization': 'Bearer {PROMPTHUB_API_KEY}'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
project_data = response.json()
formatted_request = project_data['data']['formatted_request']
variables = project_data['data']['variables']['prompt'] # Retrieve the variables section
print("Formatted Request:", formatted_request)
print("Variables:", variables)
else:
print(f"Error fetching prompt from PromptHub: {response.status_code}")
This script shows:
- How to send a GET request to our /head endpoint and retrieve a prompt
- How to structure the headers correctly
- The URL includes the project ID and specifies the branch parameter as
master(branch is optional) - Extracts the the
formatted_requestand associated variables for later use.
The response has everything you need to send to your model hosted in Bedrock. The only thing left to do is replace the variables with real app data, rather than leaving it as the default value stored in the PromptHub playground.
Replacing variables in the prompt
Now that you have the prompt and the formatted request, let’s replace the placeholder variable values with actual data.
The script will account for cases where both the system message and prompt contain variables.
One important note: Anthropic’s request structure places the system message outside of the messages array, which differs from how OpenAI handles it.
This means we need to replace variables in both the system field and the messages array.
Here’s how to replace the placeholder variable values with real values:
# Function to replace variables in the formatted request
def replace_variables_in_prompt(formatted_request, variables):
# Step 1: Replace variables in the system message
if 'system' in formatted_request:
system_message = formatted_request['system']
for var, value in variables.items():
placeholder = f"{{{{ {var} }}}}" # Identify placeholders in the system message
if placeholder in system_message:
system_message = system_message.replace(placeholder, value)
formatted_request['system'] = system_message
# Step 2: Replace variables in the user message
content = formatted_request['messages'][0]['content']
for var, value in variables.items():
placeholder = f"{{{{ {var} }}}}" # Identify placeholders in the user message
if placeholder in content:
content = content.replace(placeholder, value)
formatted_request['messages'][0]['content'] = content
# Final Output: Return the fully formatted request
return formatted_request
Here’s the breakdown of the variable replacement process:
- Replace system message variables:
- The script checks if the
formatted_requestcontains asystemfield. - Any placeholder variable keys in the
systemmessage (e.g.,{{ variable }}) are identified replaced with the provided variables values
- The script checks if the
- Replace user message variables:
- The script iterates over the
contentfield in themessagesarray, which contains the user prompt. - It identifies any placeholder variable keys like (e.g.,
{{ feedback }}) and replaces them with the provided variables values.
- The script iterates over the
- Flexible design:
- The script is designed to search for variables in both the system message and the prompt and replace them accordingly.
After getting the prompt from PromptHub and running this script you’ll have a prompt with dynamic data from your app. Now all that’s left is to send the request to your model in Bedrock.
Sending the prompt to a model hosted in Amazon Bedrock
Now that we’ve gotten our prompt and replaced the variable values, the request is ready to be sent to a model hosted in Amazon Bedrock.
PromptHub integrates directly with a variety of models hosted in Bedrock, so we will have most if not all of the required information already (like the model URL).
We’ll walk through the process of testing this locally.
1. Set up the Bedrock client
The first step is to make sure your AWS credentials are set up locally via the AWS CLI or environment variables. Then, initialize the Bedrock client using boto3:
import boto3
import json
from botocore.exceptions import BotoCoreError, ClientError
# Initialize Bedrock client
bedrock_client = boto3.client('bedrock-runtime', region_name='us-east-1') # Replace 'us-east-1' with your region
2. Prepare the payload
Convert the formatted request into a payload that Bedrock can process. Note that the system field is passed separately. This is because we are using a model from Anthropic and they handle system messages outside the messages array.
def prepare_bedrock_payload(formatted_request):
return {
"system": formatted_request["system"],
"messages": formatted_request["messages"],
"max_tokens": formatted_request["max_tokens"],
"temperature": formatted_request["temperature"],
"top_p": formatted_request["top_p"]
}
3. Invoke the model
Send the payload to Amazon Bedrock using the invoke_model method.
def send_to_bedrock(client, model_id, payload):
try:
response = client.invoke_model(
modelId=model_id,
contentType="application/json",
accept="application/json",
body=json.dumps(payload)
)
response_body = json.loads(response["body"].read().decode("utf-8"))
return response_body
except (BotoCoreError, ClientError) as error:
print(f"Error invoking Bedrock model: {error}")
return None
For help configuring your headers for the request to Bedrock see the resources listed in the intro.
Using the Run a Project endpoint
Another way to programmatically interact with your prompts in PromptHub is by sending requests directly through our platform. We handle the execution and return the LLM’s output.
The /run endpoint provides a simple way to execute a prompt directly from PromptHub with your chosen model and parameters.
Unlike the /head endpoint, this endpoint proxies the request through PromptHub and uses the API key associated with your model provider (e.g., OpenAI, Google, Amazon Bedrock). It simplifies the process by combining prompt retrieval and execution into a single step.
1. Endpoint Overview
The Run a Project endpoint uses the following format:
URL:
https://app.prompthub.us/api/v1/projects/{project_id}/run
Method:
POST
Headers:
Content-Type: application/jsonAuthorization: Bearer {PROMPTHUB_API_KEY}
Request parameters:
If you don’t pass the branch or hash parameters, the endpoint defaults to the latest commit (the head) on your master or main branch.
branch(optional): Specifies the branch from which to run the project. Defaults to the main branch (master/main) if not provided.- Example:
?branch=staging
- Example:
hash(optional): Targets a specific commit within a branch. If omitted, the latest commit from the specified branch is used.- Example:
?hash=c97081db
- Example:
Request body:
You can pass any variables required by the prompt directly in the variables field.
{
"variables": {
"product_feedback": "The product is not good"
}
}
Example request
Here’s a Python script showing you could hit our /run endpoint. Note that you’ll need to provide the value for the variable in the request. In this example, we’re sending a hard-coded value of "The product is not good":
import requests
import json
url = 'https://app.prompthub.us/api/v1/projects/5474/run?branch=staging&hash=c97081db'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer {PROMPTHUB_API_KEY}'
}
data = {
"variables": {
"product_feedback": "The product is not good"
}
}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
result = response.json()
print("Prompt executed successfully!")
print("Response:", result)
else:
print(f"Error: {response.status_code}, Details: {response.text}")
Response example
A successful response will look like this:
{
"data": {
"id": 57196,
"project_id": 5474,
"transaction_id": 60888,
"previous_output_id": null,
"provider": "Amazon",
"model": "us.anthropic.claude-3-5-sonnet-20241022-v2:0",
"prompt_tokens": 23,
"completion_tokens": 49,
"total_tokens": 72,
"finish_reason": "end_turn",
"text": "Sentiment: Positive\nLength: Short\nSpecificity: Low (no specific details about what makes the product great)\nType: General praise\nActionability: Low (lacks specific feedback that could guide improvements)",
"cost": 0.000804,
"latency": 2320.38,
"network_time": 9.55,
"total_time": 2329.93,
"project": {
"id": 5474,
"type": "completion",
"name": "Product Feedback Classifier For Integrations",
"description": "Product Feedback Classifier For Integrations description placeholder",
"groups": []
}
},
"status": "OK",
"code": 200
}
Advantages of the /run endpoint
- Simplicity: No need to manage API calls to the model provider. We configure everything for you.
- Seamless execution: Combines prompt retrieval and execution into one step.
- Adaptive: Even if you change models or providers, you won’t have to change your code!
- Instant prompt updates: Prompt changes happen instantly, without needing to deploy new code (this is true for the /head endpoint as well).
Wrapping up
Integrating PromptHub with Bedrock makes the process of testing and versioning prompts while leveraging your models in Bedrock very easy. Whether you’re retrieving a prompt from your PromptHub library or proxying your LLM request directly through PromptHub, we can help make sure that the whole team can easily be involved the prompt iteration and testing process.





