
This guide is for anyone using OpenAI as their model provider.
Integrating PromptHub with OpenAI’s models makes it easy to manage, version, and execute prompts, while decoupling prompt engineering and software engineering.
In this guide, we’ll walk through how to:
- Retrieve prompts from your PromptHub library with the Get a Project’s Head (/head) endpoint and send them to OpenAI
- Populate variables with data from your application
- Send prompts to OpenAI’s API for execution using the Run a Project (/run) endpoint
- Handle responses and optimize your prompt iterations.
Before we jump in, here are a few resources you may want to open in separate tabs.
- PromptHub: PromptHub documentation
- PromptHub: Postman public collection
- OpenAI: OpenAI documentation
Setup
Here’s what you’ll need to integrate PromptHub with OpenAI models and test locally:
- Accounts and credentials:
- A PromptHub account: Create a free account here if you don’t have one yet
- PromptHub API Key: Generate the key in your account settings
- An OpenAI API key: Grab your key from the OpenAI API dashboard
- Tools:
- Python
- Required Python libraries:
requestsandopenai
- Project setup in PromptHub:
- Create a project in PromptHub and commit an initial version. You can use our prompt generator to get a solid prompt, quickly.
- For this guide, we’ll use the following example prompt:
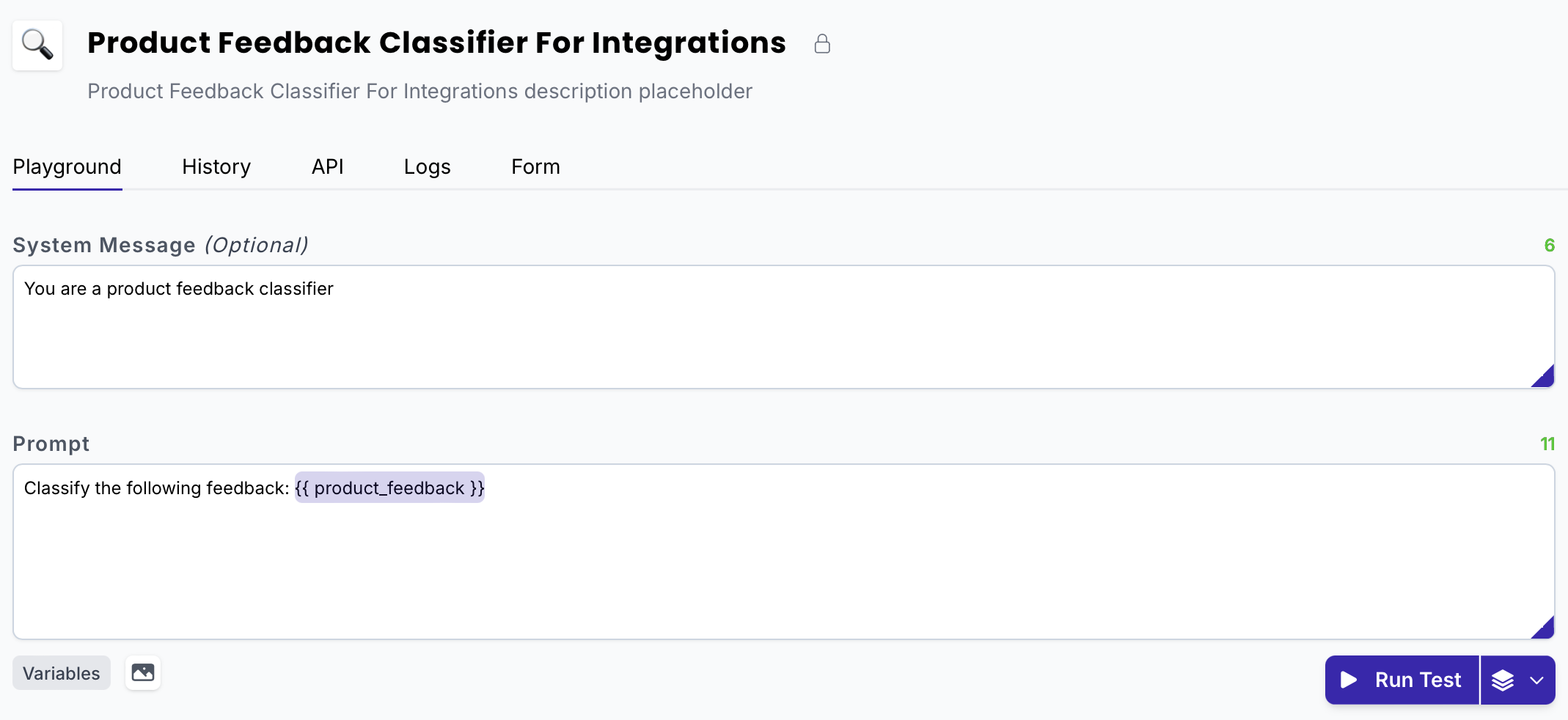
System message
You are a product feedback classifier
Prompt
Classify the following feedback: {{product_feedback}}
Retrieving a prompt from your PromptHub library
Two of our most commonly used endpoints are /head (to retrieve a prompt) and /run (to execute a prompt). We’ll start with the `/head` endpoint, which retrieves the latest version of your prompt (the head). You'll then need to make the call to the LLM yourself.
Making the request
Retrieving your prompt is straightforward. All you need is the project ID, which you can find in the URL when viewing your project or under the API tab in the project settings.
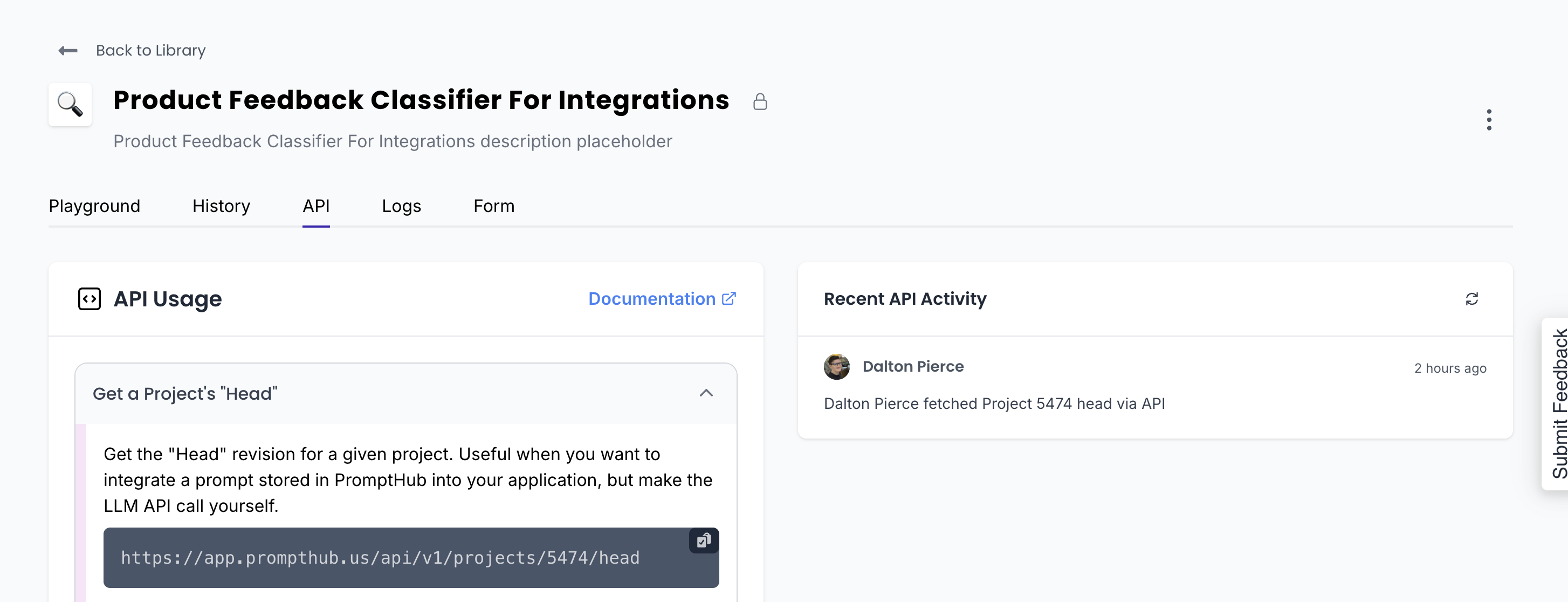
The response from this endpoint has a few important values in particular, which we'll use in later steps:
Formatted request: An object that is structured to be sent to a model. (GPT-4o, o1-mini, etc). We format it for you based on whichever model you’re using in PromptHub, so all you need to do is send it to your LLM provider. Here are a few of the more important pieces of data:Model: The model you set when committing a version in PromptHubMessages: The messages array that has the prompt and system message contentPrompt: The text of your promptMax_tokens, temperature, etc: Any parameters you set in the PromptHub playground likemax_tokens,temperature, ortop_p.
- Variables: A dictionary of the variables used in the prompt and system message, plus the value used in PromptHub. You will need to replace these variables with data from your application (more on this below).
PromptHub versions both your prompt and the model configuration, so any updates to the model will automatically reflect in your code.
In the example below, I am creating a new commit and switching from an Anthropic model via Bedrock (used when creating our Amazon Bedrock integration guide) to GPT-4o. This automatically updates the model in the formatted_request.
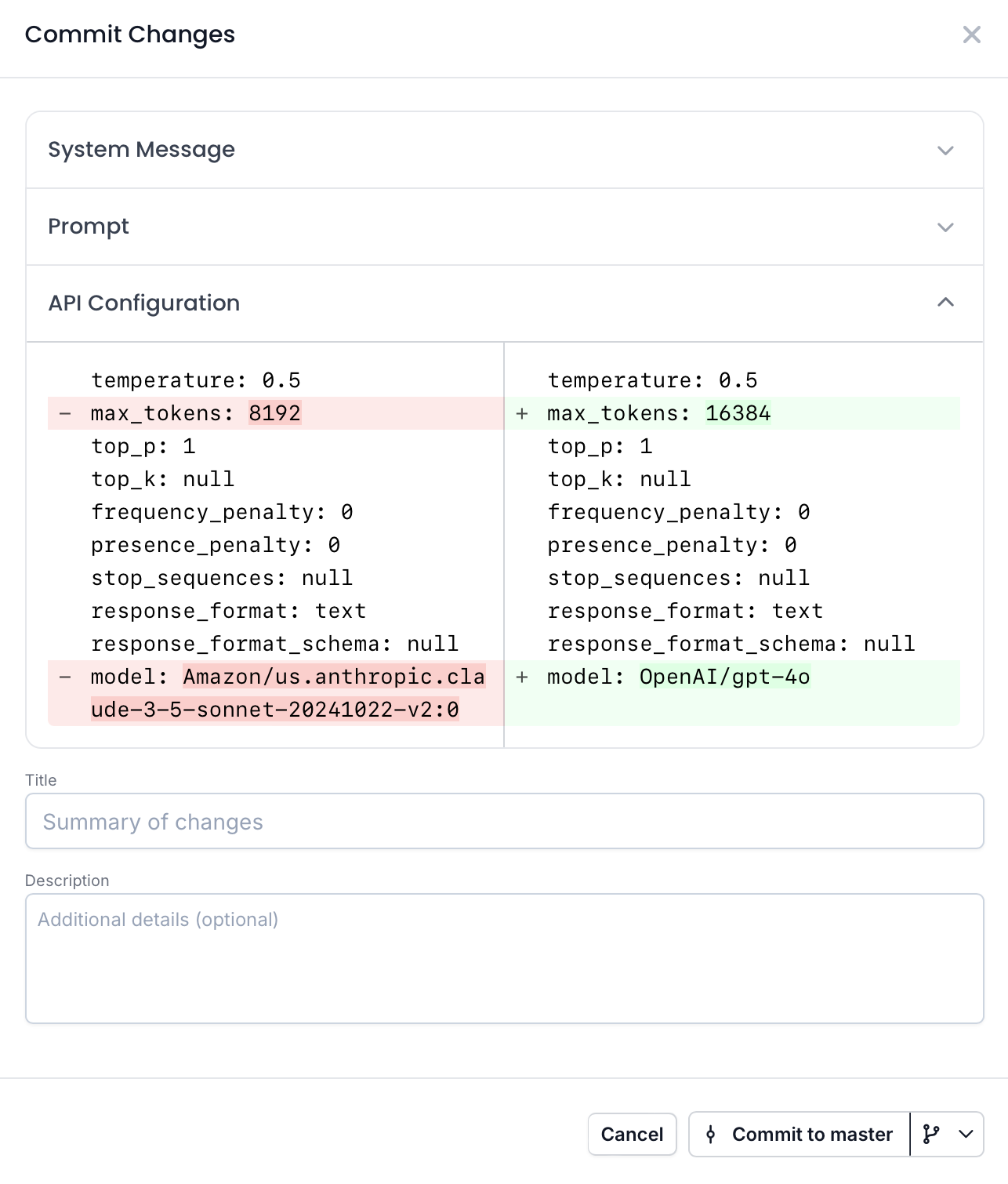
Here is what the response looks like for this endpoint for our feedback classifier example:
{
"data": {
"id": 11918,
"project_id": 5474,
"user_id": 5,
"branch_id": 8488,
"provider": "OpenAI",
"model": "gpt-4o",
"prompt": "Classify the following feedback: {{ product_feedback }}",
"system_message": "You are a product feedback classifier",
"formatted_request": {
"model": "gpt-4o",
"messages": [
{
"role": "system",
"content": "You are a product feedback classifier"
},
{
"role": "user",
"content": "Classify the following feedback: {{ product_feedback }}"
}
],
"max_tokens": 16384,
"temperature": 0.5,
"top_p": 1,
"presence_penalty": 0,
"frequency_penalty": 0,
"response_format": {
"type": "text"
},
"tools": []
},
"hash": "a09d7351",
"commit_title": "updated to gpt-4o",
"commit_description": null,
"prompt_tokens": 12,
"system_message_tokens": 7,
"created_at": "2025-01-06T14:24:11+00:00",
"variables": {
"system_message": [],
"prompt": {
"product_feedback": "the product is great!"
}
},
"project": {
"id": 5474,
"type": "completion",
"name": "Product Feedback Classifier For Integrations",
"description": "Product Feedback Classifier For Integrations description placeholder",
"groups": []
},
"branch": {
"id": 8488,
"name": "master",
"protected": true
},
"configuration": {
"id": 1210,
"max_tokens": 16384,
"temperature": 0.5,
"top_p": 1,
"top_k": null,
"presence_penalty": 0,
"frequency_penalty": 0,
"stop_sequences": null
},
"media": [],
"tools": []
},
"status": "OK",
"code": 200
}
Here is a shortened version that has the fields needed for sending the request to OpenAI:
{
"data": {
"formatted_request": {
"model": "gpt-4o",
"messages": [
{
"role": "system",
"content": "You are a product feedback classifier"
},
{
"role": "user",
"content": "Classify the following feedback: {{ product_feedback }}"
}
],
"max_tokens": 8192,
"temperature": 0.5,
"top_p": 1,
"stream": false
},
"variables": {
"product_feedback": "the product is great!"
}
},
"status": "OK",
"code": 200
}
With the response structure in mind, here’s an example of a Python script we can use to:
- Retrieve the prompt
- Extract the
formatted_requestandvariablesto use in the request to OpenAI
import requests
# Replace with your project ID and PromptHub API key
project_id = '5474'
url = f'https://app.prompthub.us/api/v1/projects/{project_id}/head?branch=master'
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json',
'Authorization': 'Bearer {PROMPTHUB_API_KEY}'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
project_data = response.json()
formatted_request = project_data['data']['formatted_request']
variables = project_data['data']['variables']['prompt'] #no variablaes in the system message
print("Formatted Request:", formatted_request)
print("Variables:", variables)
else:
print(f"Error fetching prompt: {response.status_code}")
Using the branch query Parameter
PromptHub’s versioning system allows you to manage prompts and configurations across different branches.
By including the branch parameter in your API request, you can fetch a prompt from a specific branch, such as a staging branch. This allows you to test prompt versions in different environments and make sure they’re fully vetted before deploying to production.
For example, here is how you could retrieve a prompt from a staging branch in PromptHub:
url = f'<https://app.prompthub.us/api/v1/projects/{project_id}/head?branch=staging>'
Here is a 2-min demo on how you can create branches and move prompts from one branch to another:
We now have everything needed to send the request to OpenAI. The next step is to replace the variable placeholder in the prompt ({{ product_feedback }}) with real data.
Injecting custom data into variables
Currently, the formatted request looks like this:
{
"data": {
"formatted_request": {
"model": "gpt-4o",
"messages": [
{
"role": "system",
"content": "You are a product feedback classifier"
},
{
"role": "user",
"content": "Classify the following feedback: {{ product_feedback }}"
}
],
"max_tokens": 8192,
"temperature": 0.5,
"top_p": 1,
"stream": false
},
"variables": {
"product_feedback": "the product is great!"
}
},
"status": "OK",
"code": 200
}
Note that the variable key ( {{ product_feedback}} ) is in the prompt. Replace this with dynamic data from your application.
Here is a python script that replaces the variables in the messages array, accounting for both system and user messages:
def replace_variables_in_prompt(formatted_request, variables):
# Iterate through the messages array and replace placeholders
for message in formatted_request['messages']:
content = message['content']
for var, value in variables.items():
placeholder = f"{{{{ {var} }}}}" # Double curly braces placeholder
content = content.replace(placeholder, value)
message['content'] = content
return formatted_request
This script does the following:
- Iterates through the messages array and checks the content field of each message for any placeholder variables (e.g.,
{{ product_feedback }}) - Replaces each placeholder variable with a corresponding value
After running this script, you’ll have a fully formatted prompt that dynamically updates with data from your app, ready to send to OpenAI’s API.
Sending the prompt to an OpenAI model
Now that we’re dynamically setting the variables, all that is left to do is send the request to OpenAI. We’ll lay out the steps to test this locally.
After installing the OpenAI Python library, all you need to do is configure the API call using the data from the formatted_request.
Here’s an example Python script of how that would work:
import openai
# OpenAI API key
openai.api_key = "YOUR_OPENAI_API_KEY"
# Assume formatted_request is retrieved and variables are already replaced
# Example: from your earlier script
formatted_request = get_final_formatted_request()
# Send the request to OpenAI
response = openai.ChatCompletion.create(
model=formatted_request["model"],
messages=formatted_request["messages"],
max_tokens=formatted_request["max_tokens"],
temperature=formatted_request["temperature"],
top_p=formatted_request["top_p"]
)
# Print the response
print("Response from OpenAI:")
print(response['choices'][0]['message']['content'])
Note that we are pulling the model and parameters from the formatted_request in addition to the messages array.
Bringing it all together
Here’s a single script that combines all three steps: retrieving the prompt, replacing variables, and calling OpenAI.
import requests
import openai
# Configuration
PROMPTHUB_API_KEY = "YOUR_PROMPTHUB_API_KEY"
OPENAI_API_KEY = "YOUR_OPENAI_API_KEY"
PROJECT_ID = "5474" # Replace with your PromptHub project ID
BRANCH = "master" # Specify the branch, e.g., 'master' or 'staging'
# Step 1: Retrieve the prompt from PromptHub
def get_formatted_request():
url = f'https://app.prompthub.us/api/v1/projects/{PROJECT_ID}/head?branch={BRANCH}'
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json',
'Authorization': f'Bearer {PROMPTHUB_API_KEY}'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
project_data = response.json()
return project_data['data']['formatted_request'], project_data['data']['variables']['prompt']
else:
raise Exception(f"Error fetching prompt: {response.status_code}")
# Step 2: Replace placeholder variables in the prompt
def replace_variables_in_prompt(formatted_request, variables):
for message in formatted_request['messages']:
content = message['content']
for var, value in variables.items():
placeholder = f"{{{{ {var} }}}}"
content = content.replace(placeholder, value)
message['content'] = content
return formatted_request
# Step 3: Send the formatted request to OpenAI
def send_to_openai(formatted_request):
openai.api_key = OPENAI_API_KEY
response = openai.ChatCompletion.create(
model=formatted_request["model"],
messages=formatted_request["messages"],
max_tokens=formatted_request["max_tokens"],
temperature=formatted_request["temperature"],
top_p=formatted_request["top_p"]
)
return response['choices'][0]['message']['content']
# Step 4: Test the integration with a hardcoded value
if __name__ == "__main__":
try:
# Retrieve the formatted request and variables
formatted_request, variables = get_formatted_request()
# Hardcode a test value for product_feedback
variables["product_feedback"] = "The product is not good"
# Replace the variable values in the formatted request
final_request = replace_variables_in_prompt(formatted_request, variables)
# Send the prompt to OpenAI and get the response
result = send_to_openai(final_request)
print("Response from OpenAI:", result)
except Exception as e:
print(f"Error: {e}")
Using the /head endpoint to retrieve prompts has the following benefits:
- Implement once, update automatically: Set up the code once, and any prompt updates in PromptHub automatically reflect in your app.
- Separate prompts from code: Update prompts, models, or parameters without deploying new code.
- Version control for prompts: Always retrieve the latest committed prompt
- Environment-specific prompts: Use the
branchparameter to test new prompt versions in staging without affecting production. - Data stays in your system: Sensitive data is not passed through PromptHub or logged
Executing a prompt using the /run Endpoint
Another way to interact with your prompts in PromptHub is by sending requests directly through our platform. We handle the execution and return the LLM’s output to you.
You can pass the variables at runtime which is slightly easier as well.
Requests will be logged under the 'Logs' tab for the project, allowing you to track usage.
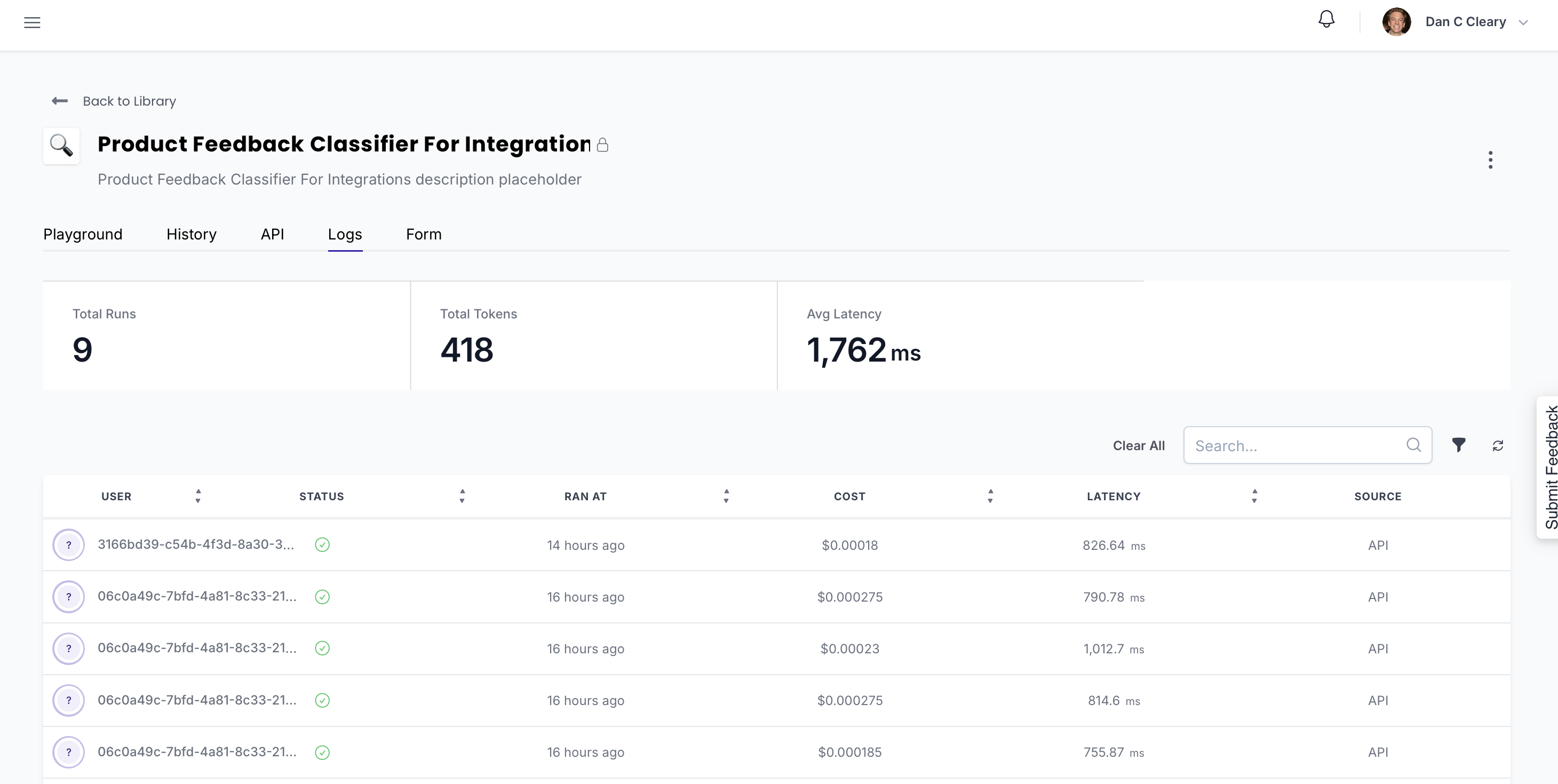
Making the request
To get started, you’ll need the project ID. You’ll find it in the URL when viewing your project or under the API tab in the project settings.
Request structure
URL:
https://app.prompthub.us/api/v1/projects/{project_id}/run
Method:
POST
Headers:
Content-Type: application/jsonAuthorization: Bearer {PROMPTHUB_API_KEY}
Request body: Provide variable values to dynamically update your prompt
{
"variables": {
"product_feedback": "The product is not good"
}
}
Request parameters:
If you don’t pass the branch or hash parameters, the endpoint defaults to the latest commit (the head) on your master or main branch.
branch(optional): Specifies the branch from which to run the project. Defaults to the main branch (master/main) if not provided.- Example:
?branch=staging
- Example:
hash(optional): Targets a specific commit within a branch. If omitted, the latest commit from the specified branch is used.- Example:
?hash=c97081db
- Example:
You can view and manage branches, along with the commit hashes, in the History tab.

Example Python script
Here’s an example of how to use the /run endpoint to execute a project with a specific variable value and print the model’s output from the response:
import requests
# Configuration
PROMPTHUB_API_KEY = "YOUR_PROMPTHUB_API_KEY"
PROJECT_ID = "5474" # Replace with your PromptHub project ID
RUN_ENDPOINT_URL = f'https://app.prompthub.us/api/v1/projects/{PROJECT_ID}/run'
# Function to run a project using the /run endpoint
def run_project_with_variables(variables, branch="master"):
url = f"{RUN_ENDPOINT_URL}?branch={branch}"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {PROMPTHUB_API_KEY}"
}
payload = {"variables": variables}
response = requests.post(url, headers=headers, json=payload)
if response.status_code in [200, 201]:
result = response.json()
print("LLM Output:", result['data']['text']) # Print only the LLM output
else:
print(f"Error: {response.status_code}, {response.text}")
# Hardcoded test variables for testing
test_variables = {
"product_feedback": "The product is not good"
}
if __name__ == "__main__":
try:
# Run the project with test variables
run_project_with_variables(test_variables)
except Exception as e:
print(f"An error occurred: {e}")
Example response
The text field will contain the response from the model.
{
"data": {
"id": 57230,
"project_id": 5474,
"transaction_id": 60926,
"previous_output_id": null,
"provider": "OpenAI",
"model": "gpt-4o-2024-08-06",
"prompt_tokens": 27,
"completion_tokens": 3,
"total_tokens": 30,
"finish_reason": "stop",
"text": "Positive feedback",
"cost": 0.00017999999999999998,
"latency": 529.75,
"network_time": 1.78,
"total_time": 531.53,
"project": {
"id": 5474,
"type": "completion",
"name": "Product Feedback Classifier For Integrations",
"description": "Product Feedback Classifier For Integrations description placeholder",
"groups": []
}
},
"status": "OK",
"code": 200
}
When to use the /run Endpoint
- Easy integration: Reduces the need for additional API calls and streamlines the process.
- Easily switch models and providers: You can swap models or providers through commits on PromptHub, no code changes required.
- Take advantage of PromptHub’s monitoring features: The
/runendpoint logs requests in the PromptHub dashboard, providing insights into how users interact with your prompts.
Wrapping up
Integrating PromptHub with OpenAI’s API makes it easy to manage, test, deploy, and update prompts as you make changes. Whether you’re retrieving prompts from your PromptHub library and calling the model yourself, or running LLM requests directly through our /run endpoint, PromptHub simplifies collaboration and ensures anyone on your team (with the right permissions) can iterate on prompts.





